こんにちは,LegalForce R&D セクションでエンジニアをしている打田(@moco_beta)です。
LegalForce では,お客様がアップロードした契約書を条文単位で検索ができる,条文検索機能を提供しています。AIによるレビュー支援機能を補完する形でよく利用されている機能ですが,「どんなキーワードで検索したらいいのかわからない」という声をいただくことが増えてきました。検索キーワードの発見に役立ててもらうため,先日 Query Auto Completion(クエリ自動補完,以下 QAC)(*1) をリリースしたので,その裏側をご紹介したいと思います。
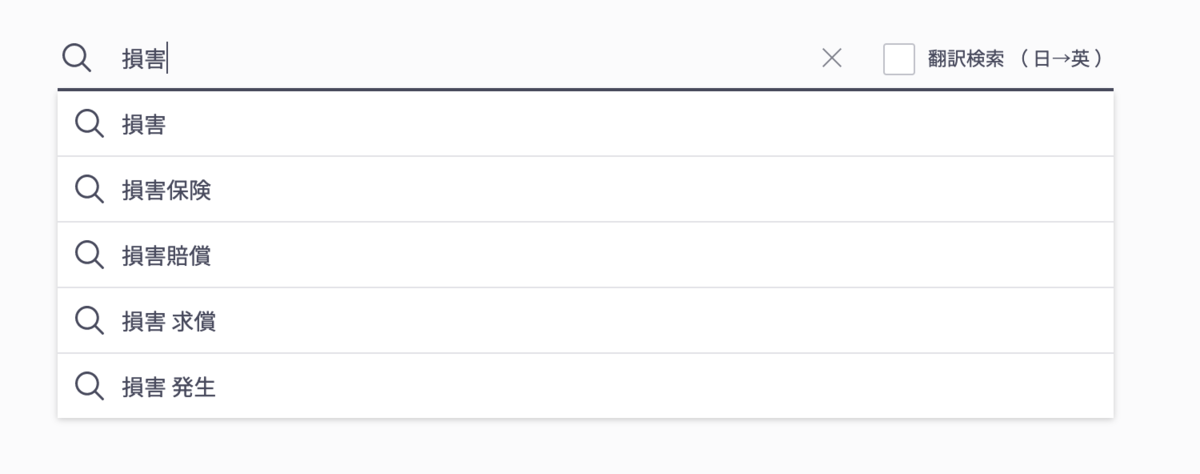
(*1) 検索キーワードの一部を入力フォームに入れると,フォームの下にドロップダウンリストでキーワード候補が出てくる機能を指します。
QAC 開発における課題
LegalForce で,使い勝手の良い QAC を開発するにあたって,2つの課題がありました。1つはマルチテナンシー(*2) にまつわる問題,もう1つは日本語入力にまつわる問題です。
(*2) ソフトウェアプロダクト,インフラストラクチャーを複数の顧客(テナント)で共有するモデル。データはテナントごとに異なり,分離されている。
クエリログ不足(コールドスタート)問題
QAC のデータ(キーワード候補)は一般に,クエリログから作成することが多いのですが,LegalForce はマルチテナンシー下で運用されているサービスで,潤沢なクエリログがすべてのテナントにおいて入手できるとは限りません。また,専門性の高い BtoB サービスであるため,テナントごとのユーザー数も限られます。そこで,テナントごとのクエリログを利用する以外のデータ作成方法を検討する必要がありました。
日本語入力(IME)にまつわる問題
日本語向けの QAC を実装するにあたって,日本語入力(IME)は悩ましい問題です。ひらがな,カタカナ,漢字変換ミスや漢字変換途中の入力,といった様々な入力パターンに対応するために,キーワード候補とユーザー入力の双方をローマ字に変換してからマッチさせる手法が採用されることが多いです。しかし,その実装はあまり簡単ではなく,例えば Elasticsearch の out-of-the-box で使える kuromoji_readingform filter では使い勝手の良い QAC を実装することができません(*3)。心地良い自動補完を実現するためには,入力解析コンポーネントの実装を工夫する必要があります。
(*3) kuromoji_readingform は(修正)ヘボン式 ローマ字を採用しているが,ローマ字表記には他にも訓令式があり,例えば「しゃ」を表記するときにヘボン式では「sha」,訓令式では「sya」というような違いがある。また,日本語入力システムではヘボン式でも訓令式でもない,ワープロ式(長音符号つき文字「Tōkyō」や「Tôkyô」を使わずに母音を重ねる,などの特徴がある)と呼ばれる変換方式が広く用いられている。
対策と実装
テナント共通キーワード辞書とテナント別キーワード辞書
1つめの,クエリログ不足問題に対処するため,まずは全テナント共通で使える QAC 用のキーワード(クエリ)候補辞書を整備していく方針をとることにしました。この辞書は,ドメインスペシャリストの知識や,テナント横断で集計したクエリログを活用して作成します。LegalForce では現在,日本語と英語の契約書を扱っており,日英合計で6000件程度の辞書を初期リリース用に構築しました。例えば,以下のような語がキーワード候補辞書に含まれます。
日本語
秘密保持 反社会的勢力 ライセンス 独占的
英語
agreement is terminated shareholder consent secrecy information
ただし,共通のキーワード候補辞書をすべてのテナントにそのまま適用してしまうと,ユーザーを 0 件ヒットの検索結果に誘導してしまう,という問題が発生します。テナントごとにコーパス(ドキュメントコレクション)が異なるため,あるテナントでは沢山のドキュメントがヒットするキーワードが,他のテナントでは 0 件ヒットとなってしまうケースが十分考えられるためです。そのため,共通キーワード候補辞書から,さらにテナントごとのキーワード候補辞書を作成しました。テナントごとのキーワード候補辞書は,「そのテナントのコーパスを検索した時に,1件以上ヒットする」キーワードのみを格納したもので,こちらは日々変わっていくコーパスに追従していく必要があります。
テナント別キーワード候補辞書のメンテナンスシステムの構成を図に示します。大きく,新規キーワード(ドキュメント追加により,新しく検索ヒットするようになったキーワード)の登録コンポーネントと,古くなったキーワード(ドキュメント削除により,0件ヒットになったキーワード)の削除コンポーネントからなります。いずれも ECS (Fargate) で常駐プロセスとして稼働しており,テナントのコーパス変更に追従する形で,キーワード候補を最新の状態に保ちます。また,「1件以上ヒットするキーワード」を効率的に探すため,Elasticsearch の Percolate query を活用しています。
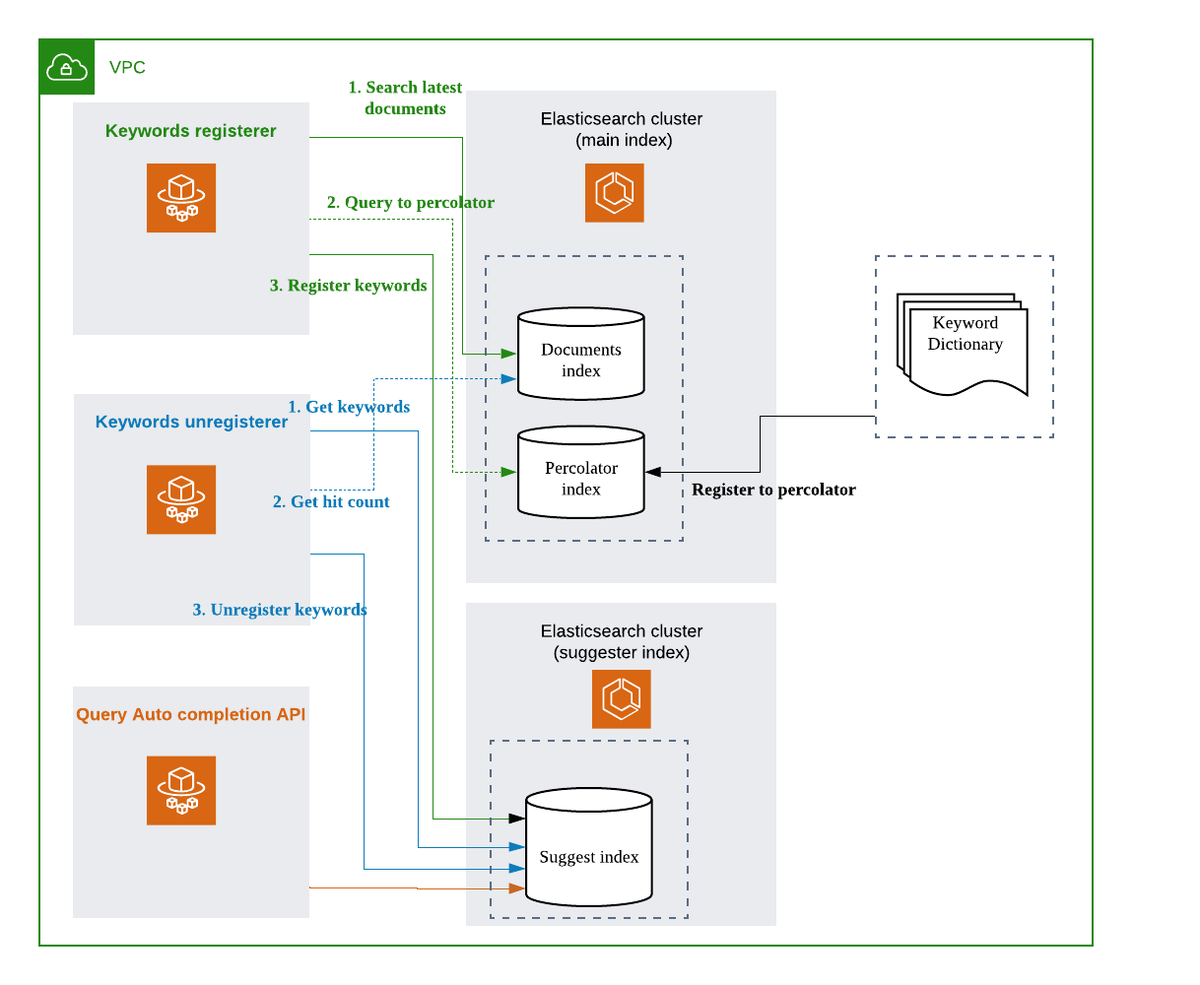
なお図に示しているように,QAC のバックエンドには Elasticsearch を使っており,メインのインデックスとは別クラスタで稼働させています。サービングも専用の HTTP API を用意して,メインの検索システムとは切り離して運用しています。
日本語 auto completion 用 analyzer
2つめの,日本語入力にまつわる問題に対処するには,検索エンジンの機能を活用する,自前で QAC のシステムを自作する,などいくつかの方法が考えられます。本システムでは,Completion キーワードの高速なルックアップができる Elasticsearch の Completion Suggesters を利用することとし,Completion Suggester 向けのカスタム日本語 token filter と,それを呼び出すための Elasticsearch の analysis プラグインを作成しました。(なお,Completion Suggester と比べると性能面では少し不利ですが,カスタマイズが不要な実装方法が Elastic公式ブログ で紹介されています。)
作成した analysis プラグインは, JapaneseTokenizer (kuromoji) で形態素解析を行い,読みのフィールドをローマ字に変換するものです。 kuromoji_readingform とよく似ていますが,ヘボン式,訓令式,ワープロ式のすべてのローマ字表記・変換方式に対応し,また,漢字変換途中の入力にも対応できるように工夫をしました。例えば,「損害賠償」「反社」という単語をカスタム analysis プラグインで解析すると,以下のトークンが出力されます。(_analyze API のレスポンスには他に offset 情報なども含まれますが,見やすさのため,tokenとposition情報のみ記載しています 。)
「損害賠償」の解析結果
curl -XPOST "http://localhost:9200/suggesters_test/_analyze?pretty" -H 'Content-Type: application/json' -d'{ "text": "損害賠償", "analyzer": "kuromoji_compl_index"}'
{
"tokens" : [
{
"token" : "損害",
"position" : 0
},
{
"token" : "songai",
"position" : 0
},
{
"token" : "sonngai",
"position" : 0
},
{
"token" : "son'gai",
"position" : 0
},
{
"token" : "賠償",
"position" : 1
},
{
"token" : "baisyou",
"position" : 1
},
{
"token" : "baishou",
"position" : 1
}
]
}
「反社」の解析結果
curl -XPOST "http://localhost:9200/suggesters_test/_analyze?pretty" -H 'Content-Type: application/json' -d'{ "text": "反社", "analyzer": "kuromoji_compl_index"}'
{
"tokens" : [
{
"token" : "反",
"position" : 0
},
{
"token" : "han",
"position" : 0
},
{
"token" : "hann",
"position" : 0
},
{
"token" : "han'",
"position" : 0
},
{
"token" : "社",
"position" : 1
},
{
"token" : "sya",
"position" : 1
},
{
"token" : "sha",
"position" : 1
}
]
}
「しゃ」については「sya」と「sha」,「ん」については「n」「nn」「n'」など,複数のローマ字入力方式で展開されていることがわかります。また,正しい読みが取得できなかった場合も想定して,オリジナルのトークンも出力しています。(カスタム token filter やプラグインの実装については,ここでは詳しく触れませんが,また別の機会で紹介できればと思います。)
この analysis プラグインと Completion Suggester を組み合わせることで,以下のような,様々な入力に対応した QAC システムが構築できました。
ひらがな

ローマ字(読み)
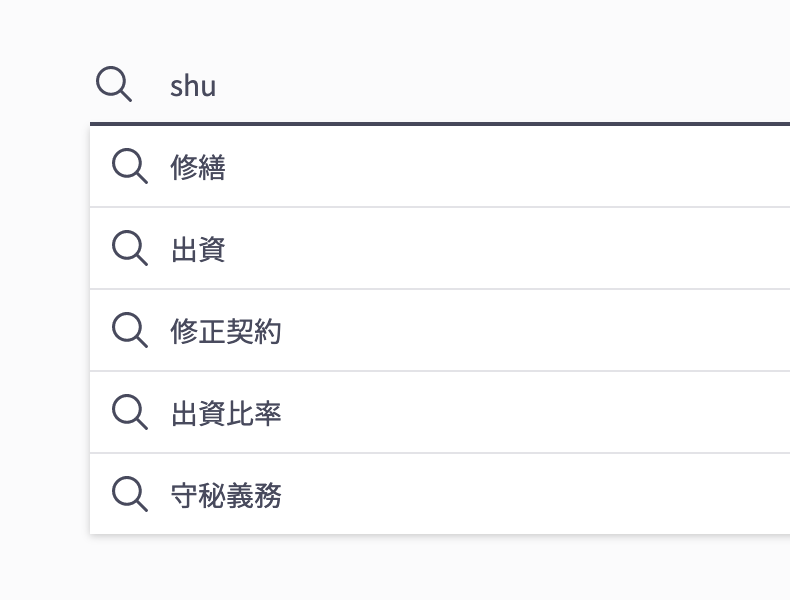
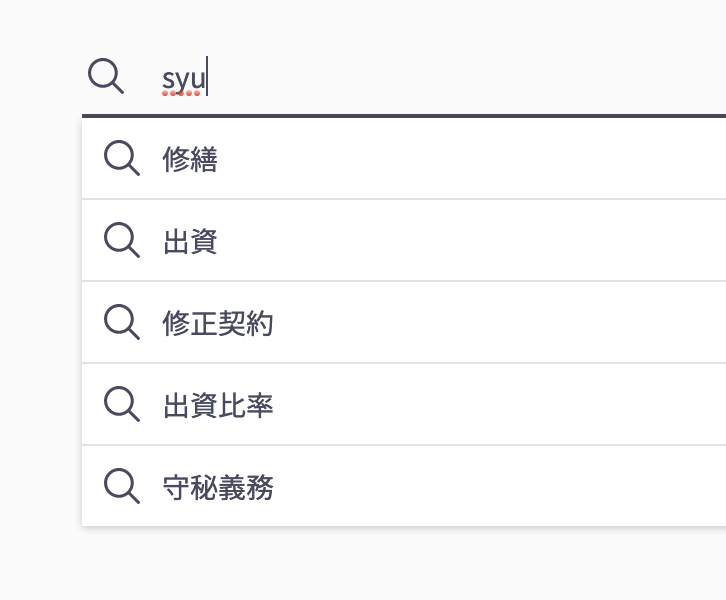
漢字変換中

QAC では1文字タイプするごとにレスポンスを返さないといけないため,サクサク動作するだろうか...という懸念がありましたが,バックエンドに高速な Completion Suggester を使っていることで,タイムラグをほぼ感じさせない応答速度が実現できました。
KPI への貢献
QAC 機能は,検索システムのユーザビリティ向上を目的としており,KPI 設定が難しいため,数値目標などは設定しませんでした(例えば,検索回数などの指標は下がる可能性がある)。一方で,リリースしてからまだ1ヶ月程度で様子を見ている段階ですが,条文検索の利用率(アクティブユーザーのうち,条文検索機能を利用したユーザーの割合)が好調に推移しており,また,QAC を利用した(提示されたキーワード候補をクリックした)ユーザーのほうが,継続的に条文検索を利用する割合が他のユーザーよりも高い傾向があるようです。
今後改善したいこと
今回,初期のリリースでは,QAC システムの基盤をしっかり整えることを重視し,「どのようなキーワード候補をどのような順番で表示(ランキング)するのが最適なのか」についてはまだまだ改善の余地があります。今後は,テナント別の検索クエリログや QAC のクリックログを用いて,よりきめ細かくユーザーの検索ニーズに応えるシステムにしていきたいと考えています。
まとめ
本記事では,駆け足ではありますが,LegalForce 条文検索機能のための Query Auto Completion 開発にあたっての悩みどころと解決策について紹介しました。
LegalForce R&D チームでは,全文検索や類似文書検索が好きな検索エンジニア🔎を募集しています!
https://www.wantedly.com/projects/536545
検索エンジン(Elasticsearch / Lucene)が好きな人や,自然言語処理や機械学習を活用した機能開発,精度改善が好きな人が特に活躍できるポジションです。いますぐ転職は考えていないけれどカジュアル面談でちょっと話を聞いてみたいという方も,気軽にご応募ください!