はじめに
LegalOn Technologiesが提供する「LegalOn: World Leading Legal AI」は、契約書ドラフト・レビューや案件の管理、法務相談まで、法務業務をワンストップで支援する革新的なサービスです。リリースから1年半、企画開始から約2年半が経った今、プロジェクト立ち上げの背景、開発の進め方、これまでの振り返りや今後の展望、さらには技術面での学びまでを、全9回にわたるブログシリーズとしてお届けしていきます。
第8回となる本記事では、「LegalOn」の中核を担う検索システムの開発に焦点を当て、その立ち上げから運用、そして未来への展望までを、CTOオフィスリーダーの時武が以下の2名に話を聞きました。
- 打田:Staff Engineer
- 浅野:Staff Engineer
「LegalOn」の検索システムで採用された主要な技術スタックは以下です。
| Category | Technology Stack |
|---|---|
| 言語 | Python |
| 検索エンジン | Elasticsearch (ECK) |
| プラットフォーム | Google Cloud |
| 構成管理 | Terraform |
| コンピューティング基盤 | Google Kubernetes Engine (GKE) |
| LLM | Azure OpenAI Service, Google Gemini API |
| CI/CD | GitHub Actions |
| モニタリング | Cloud Monitoring, Datadog |
開発初期の設計思想と技術選定
小規模チームでの立ち上げとビジョンの共有
時武 まずは「LegalOn」の検索システム開発が始まった当初、どんな状況だったのかを教えていただけますか?
打田 「LegalOn」の構想は、2022年12月頃の製品戦略議論から始まりました。2023年4月から開発が本格的に開始されたのですが、検索チームは当時、5〜6名程度の小規模なチームでした。その中で、製品の中核機能を担当することになったんです。開発項目も膨大で、正直立ち上がりは遅くなってしまったのが本音ですね。
浅野 私は2023年2月に入社し、ちょうど「LegalOn」の開発が開始するタイミングでした。私がチームに加わった時は、既に全体のアーキテクチャは決まっていましたが、検索・推薦基盤周りはゼロの状態からのスタートだったので、考えることが非常に多かったです。メインの仕事は基盤周りの設計と実装、そしてコードレビューでした。
時武 小規模なチームで中核機能を担うとなると、プレッシャーも大きかったのではないでしょうか。プロジェクト開始当初、現場の雰囲気はどうでしたか?
打田 私は経営層から直接「検索とレコメンデーションをプロダクトの中心にしたい」と聞いていて、それ自体はポジティブに受け止めていました。ただ、その構想や温度感を現場のメンバーにうまく伝えられず、開発当初は既存プロダクトの「LegalForce」と「LegalForceキャビネ」を統合するくらいの印象だったと思います。 一方で、開発項目が非常に多く物量の多さに苦しさを感じていて、プロジェクトの構想と現場の温度感に乖離があり、最初は「どうしよう」と一人で悩んでいましたね。
時武 その状況をどのように乗り越えたのでしょうか?
打田 2023年の7月頃にCPOの谷口さんを招き、「LegalOn」のビジョン共有会を実施しました。谷口さんから直接「LegalOn」の構想や、検索の機能がいかに重要かをひたすら語ってもらったことで、メンバーが自分たちの仕事が事業全体の中でどのようにインパクトを与えることができるのか俯瞰的に見られるようになり、チーム全体のコミットメントとオーナーシップが向上しました。谷口さんに直接話してもらってよかったなと思いますね。
時武 ただ言われたことをやるのと自分の仕事を事業目線で俯瞰して見れるようになるのは、とても大きな違いですよね。
技術選定の工夫と価値向上への貢献
時武 検索システムのアーキテクチャや技術選定についてはいかがでしたか?
浅野 インフラ周りでは Kubernetes を使うことが決まっていましたが、その上で Elasticsearch をどう実現するかが課題でした。当時 Kubernetes 上で Elasticsearch を動かす事例があまりなく、新しい組み合わせでしたが、 Elasticsearch を Kubernetes 上で運用するためのオペレーターであるECK( Elastic Cloud on Kubernetes )を検証し、なんとか動きそうだというので本番導入しました(笑)
結果的に計算リソースなどの管理を自動化でき、運用コストも大幅に削減できました。リリース後も想定以上に安定稼働しており、非常にうまくいった点だと感じています。
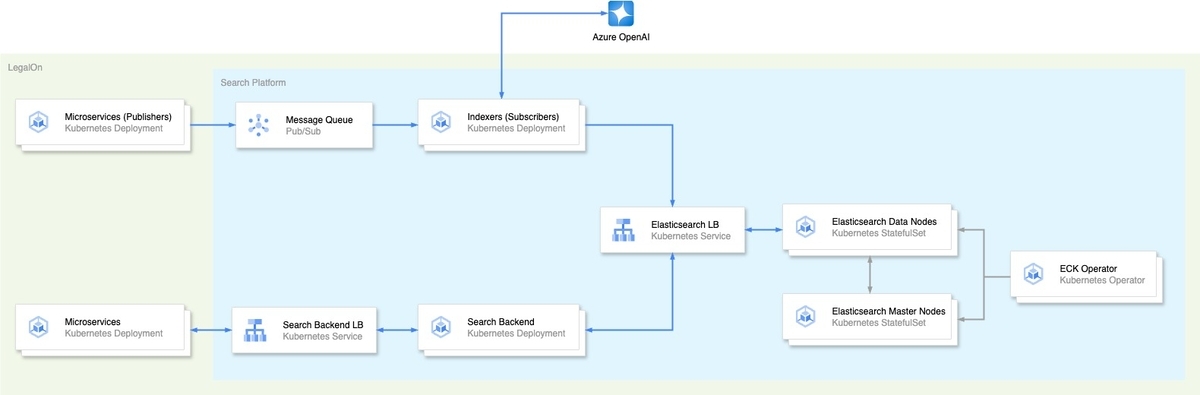
浅野 そうですね、インデクシングのスピードも「LegalOn」のリリース当初に比べて大きく改善することができました。データパイプライン周りの課題を解決する中で、最終的にはインデクシングの速度が20倍に向上させることができました。リアルISUCONのような体験でしたね(笑)
時武 当時「インデクシングの速度が20倍に向上」という社内リリースを受けてすごく興奮したのも覚えています!その他に、プロダクト全体の価値向上に貢献できた点はありますか?
打田 「LegalOnアシスタント」の導入ですかね。当初の「LegalOn」のリリース計画には含まれていなかったのですが、ちょうどChatGPTの盛り上がりと時期が重なり、RAGシステムをプロトタイピングした結果、経営層から「ファーストリリースで入れたい」という強い要望がありました。元々ファーストリリース後の機能追加としてのリリースを想定していたので、「今は忙しすぎるから無理です」と反対しましたが(笑)、やはりこのAIの時代に乗っていくためには絶対必要な機能だということで最終的にタイトなスケジュールの中で組み込む判断をしました。 結果的にプロダクトの価値向上に大きく貢献できたと感じているので、組み込む判断は正解だったと今は思いますね。
経験から得た課題と反省点
時武 一方で、「ここはもっとこうしておけばよかった」という反省点や課題について教えてください。
打田 開発前の設計フェーズで、チームメンバーのオーナーシップが弱く、全員が「自分ごと」として捉えられていなかったために、設計が「ふんわり」としたまま進んでしまったことです。その結果、実装段階で仕様漏れや検討漏れが噴出し、実装が忙しくなってしまいました。もう少し早い段階で私から「LegalOn」の構想をうまく共有できていれば、全員がオーナーシップを持って動けて、実装にもっと余裕があったのではと反省しています。
浅野 リリース直前のインデクシング周りの課題も大変でしたね。元々データパイプラインには Dataflow を使っていましたが、Pub/Subとの相性が悪く、チーム内に知見が不足していたため、直前になって検証が非常に難航しました。さらに、検索エンジンから案件一覧などの画面を出す設計だったため、検索エンジンの一貫性が崩れると製品にダイレクトに影響が出てしまう、という高い要求水準もプレッシャーでした。
時武 とはいえ設計段階で予見するのは難しかったと思いますが、今振り返ると回避できる策はありましたか?
浅野 はい、 Elasticsearch には「楽観ロック(楽観的並行性)」という仕組みが元々備わっています。最初からこれを設計に組み込んでいれば、データの整合性を保ちながらデータを入れることができ、問題を防げたと思います。
時武 なるほど。ちなみに検索システムにおける一貫性って、一般的にはどういう考え方があるのでしょうか?
浅野 一般的に、 Elasticsearch だけで製品を作ることは少なく、RDBが中心です。RDBでしっかりデータ基盤を構築して、検索エンジンを使う場合はRTPのデータを同期していくみたいなイメージですね。 検索エンジンはどうしても同期に遅延があるので、「ある瞬間の完全一致」ではなく、時間が経つと最終的に整合する「結果整合性」を期待するのが主流だと思います。 「LegalForceキャビネ」時代に Elasticsearch をDBとして使っていた問題を「LegalOn」で解消できたのは良かったと思います。
時武 リリースまでの1年を振り返ってみていかがですか?
浅野 振り返ると、こうすればよかったという反省点もありますが、全体としてタイトなスケジュールの中でなんとか形にできたのは良かったと思います。「LegalOn」の開発中も優秀なメンバーがどんどん入ってくれて、自分自身も身が引き締まる思いでした。 そもそも、1年でこの規模の新規製品開発をやり遂げたこと自体がすごいことで、それを実現できたのはLegalOn Technologiesの開発組織の底力だと思いました。普通の会社では数年かかるような規模の開発を、優秀なエンジニアが力を発揮して、PdMもうまく落としどころを作ってくれたおかげで、大きな障害もなく春にリリースできたのは本当に奇跡的だったと感じています。
時武 そうですよね。日々開発に追われている時は「本当にうまくいくのか」と不安もありましたが、1年でこのレベルに仕上がったのは、事例として本当に貴重だと思います。
今後の展望 ― 精度改善と新しい挑戦
時武 これらの経験を踏まえ、今後の検索チームの展望についてはいかがでしょうか?
浅野 私は今は検索チームを離れているのですが、個人的にやり残したことはいくつかあります。たとえば、検索・推薦の精度改善への取り組みは十分でなかったように感じます。いろんな単語をSynonym辞書に登録して、略称でも検索できるようにするなど細かな改善はできていましたが、継続的にインクリメンタルに検索精度を高めていく仕組みや、推薦精度を本格的に改善していく取り組みまでは手が回りませんでした。 また、レコメンドにおいては、元々のキーワードベースで推薦する仕組みから、機械学習モデルを活用して精度を高めたいと考えていました。(現在の検索チームリーダーの吉井さんに期待しています!)他にも、データパイプラインの整合性や、再インデックスをより容易にする改善など、やりたかったことはたくさんあります。
現在の検索チームは、検索・推薦の精度や運用の改善も進めつつ、AIエージェント周りの機能開発にも関わっていてマルチに活躍している印象です。メンバーのレベルが高く、吸収も早いので、今後もエージェントを使った検索など、重要な領域に力を入れていってほしいです。
打田 私は一度LegalOn Technologiesを離れ2024年に戻ってきたのですが、戻る前から検索チームの採用が進んでいて、「忙しいけど、私が戻らないといけない状態ではない」と聞いていました。実際、「LegalOn」のリリースから1年経っても検索システムに大きな障害はなく、非常に安定して稼働しているのは大きな成果だと思うので、今後も期待しています。ECKの導入による自動化も、運用コストの削減に大きく貢献しています。
また、先ほどお話しした「LegalOnアシスタント」の開発は、今ではプロダクトの価値向上に大きく貢献できたとポジティブに捉えています。RAGシステムは今では「コンテキストエンジニアリング」という文脈で、LLMに与えるコンテキストの重要な一部として位置づけられるようになっています。検索の延長線上にある新しい形のRAGシステムは、今後もAIシステムのコアとして発展し続けると思います。検索チームには、ぜひそこをさらに推し進めていただきたいです。
仲間募集!
LegalOn Technologiesでは、「Product Centric(全員がプロダクトの価値向上のために活動する)」を大切にし、学ぶことに前向きで、挑戦を楽しめるエンジニアを募集しています。今回触れたような技術的な挑戦や、チームで課題を解決していくプロセスに興味を持たれた方は、ぜひ以下の採用サイトをご覧ください。皆さんのご応募をお待ちしております!
次回は、最終回「第9回「LegalOn」誕生の裏側:品質編」をお届けいたします。