こんにちは、LegalOn Technologiesでエンジニアをしている神田(@kampersanda)です。
この記事の内容
Elasticsearch の Character Filter でユニコード正規化を適用したとき、Tokenizer の結果によってはトークンのオフセットに不正な値が入るバグが報告されています。
頻繁に起こるケースでは無いのですが、実際にデータを Elasticsearch に取り込む際に発生しており、恒久的な対応が必要です。本記事では、そのバグの内容と原因を説明し、その Workaround を提案します。
本記事で想定する Lucene/Elasticsearch のバージョンは以下です。
- Lucene: 9.8.0
- Elasticsearch: 8.11.1
本記事は、Elasticsearch の基本的な使い方(リクエストの投げ方など)はある程度知っている前提で記述します。
追記(2024-06-02):この内容は Search Engineering Tech Talk 2024 Spring で発表しました。その際のスライドを以下に公開しました。
Analyzer の説明
事前知識として、簡単に Elasticsearch の Analyzer について説明します。
Elasticsearch では、Character Filter → Tokenizer → Token Filter の順に入力文を処理し、登録や検索を実行します(下図)。
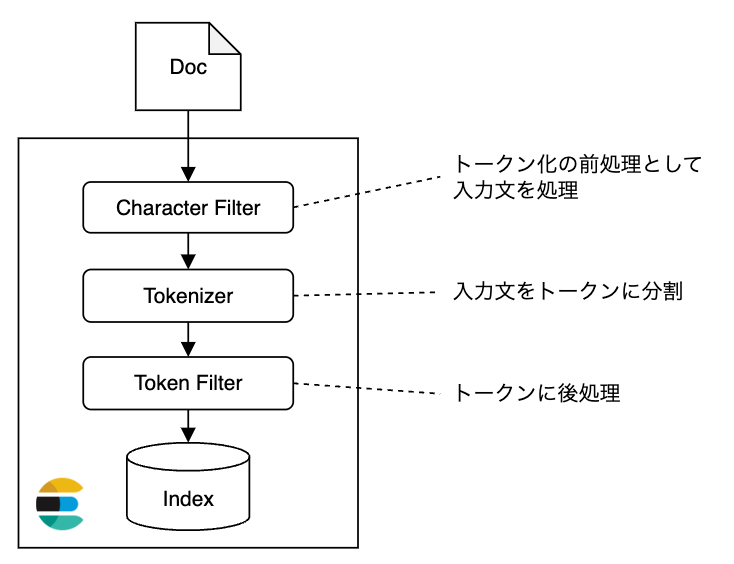
各コンポーネントは、以下のような働きをします。
- Character Filter は、Tokenizer の前処理として入力文を処理します。ユニコード正規化やHTMLタグ除去が行われることが多いです。
- Tokenizer は、入力文をトークンに分割します。英語では空白で区切ったり、日本語では Kuromoji などの形態素解析器を用いたりすることが多いです。
- Token Filter は、Tokenizer により得られたトークンに後処理をします。ストップワードを削除したりすることが多いです。
簡単な例
以下は、Character Filter に icu_normalizer、Tokenizer に standard、Token Filter に何も指定しない Analyzer の例です。
$ curl -XPUT "localhost:9200/test_index" \ -H 'Content-Type: application/json' \ -d ' { "settings" : { "analysis": { "analyzer": { "simple_analyzer": { "char_filter": ["icu_normalizer"], "tokenizer": "standard" } } } } }'
icu_normalizer は、入力文字にユニコード正規化を適用します。standard は、Unicode Text Segmentation アルゴリズムに基づきトークンに分割します。
この Analyzer を使って、10㌫ を解析すると以下のような結果が得られます。
curl -XPOST "http://localhost:9200/test_index/_analyze?pretty" \ -H "Content-Type: application/json" \ -d '{"analyzer": "simple_analyzer", "text": "10㌫"}' { "tokens" : [ { "token" : "10", "start_offset" : 0, "end_offset" : 2, "type" : "<NUM>", "position" : 0 }, { "token" : "パーセント", "start_offset" : 2, "end_offset" : 3, "type" : "<KATAKANA>", "position" : 1 } ] }
Character Filter によって 10㌫ が 10パーセント に正規化され、Tokenizer によって 10 と パーセント に分割されています。
start_offset と end_offset は各トークンの原文での出現位置(0-origin)を示しています。パーセント の値が start_offset=2, end_offset=3 であり、正規化前の文字の出現位置を保持していることがわかります。本記事のテーマである「トークンのオフセット」は、これらの値を指します。
バグの内容
本記事で取り扱うバグの内容と、その原因を説明します。
再現
上述の Analyzer を使って合字 ㍻ を解析します。すると、以下のような結果となります。
curl -XPOST "http://localhost:9200/test_index/_analyze?pretty" \ -H "Content-Type: application/json" \ -d '{"analyzer": "simple_analyzer", "text": "㍻"}' { "tokens" : [ { "token" : "平", "start_offset" : 0, "end_offset" : 0, # <- Bug! "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "成", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 1 } ] }
㍻ が 平成 に正規化され、その後トークン 平 と 成 に分割されています。しかし、トークン 平 が start_offset=0, end_offset=0 となっており、原文のどこにも出現しない空文字列のように扱われています。これは不正な値で、期待される範囲は start_offset=0, end_offset=1 です。
原因
これは Lucene の Character Filter の設計に起因します。以下のクラス CharFilter では、関数 correctOffset(i) = j で解析後のオフセット i から原文のオフセット j へのマッピングを管理しています。
- 開始地点:
correctOffset(0) = 0 - 終了地点:
correctOffset(1) = 1
です。
- 開始地点:
correctOffset(1) = 0 - 終了地点:
correctOffset(2) = 1
です。
correctOffset(1) について、1 と 0 の異なるオフセットへのマッピングが期待されており、期待値に一貫性が無いことがわかります。上記の例では correctOffset(1) = 0 となっていたため、トークン 平 の end_offset が不正値となりました。

現状
ユニコード正規化に限らず、Lucene で Character Filter によってトークンのオフセットがズレるバグは少なくとも2015年辺りから認識されています。
しかし現在でも Open のままであり、Lucene 側で解決されることを期待するのは難しそうです。一文字が複数のトークンに分割されることは、設計ポリシー的に想定されていないように思えます。
Workaround
根本的な解決が難しい問題のため、いくつかの Workaround から最も適切な方法を選定します。Lucene/Elasticsearch では、Character Filter → Tokenizer → Token Filter の順に入力文を処理し、登録や検索を実行します。この処理の流れを前提に、(1) どのタイミングで (2) どのように対処するかでいくつかの選択肢が考えられます。

この記事では以下の4つの対処案を提案し、それぞれの Pros/Cons について議論します。
- Elasticsearch に投入する前に、原文にユニコード正規化を適用する
- Character Filter の時点で、バグの原因となる文字以外を正規化するように修正する
- Tokenizer の時点で、バグの原因となる文字が複数のトークンに分割されないように修正する
- Token Filter の時点で、Character Filter の代わりに後処理としてユニコード正規化を適用する
1. Elasticsearch に投入前に、原文にユニコード正規化を適用する
おそらく最も単純な方法です。ユニコード正規化に関する処理を、完全に Elasticsearch の外で解決しようというアイデアです。
- Pros
- Lucene/Elasticsearch の仕様に依存しない形で解決できる
- 解析結果などの精度には影響なく解決できる
- Cons
- 保守コストが大きい
- Elasticsearch の Mappings と同期を取りつつ、Text 型フィールドやクエリに一貫性を持って適用する必要があり、コードの管理が大変です。フィールドやエントリポイントが増えるたびに抜け漏れを気にする必要があり、同時にテストコードも増えます。
- 原文が必要となった場合への対策が必要
- 正規化された文書が ES に投入されることになるので、原文は手元に無い状態となります。原文は別のフィールドとして ES に保存するか、必要になるたびに別のデータベースから取ってくるなどの対策が必要になります。
- 正規化された文が結果として返る
- 正規化された文が ES には保存されるので、検索結果として返るスニペットなども正規化された内容となります。
- 保守コストが大きい
2. Character Filter の時点で、バグの原因となる文字以外を正規化するように修正する
ICU normalization character filter には、unicode_set_filter という正規化する/しない文字を正規表現で指定できるオプションが存在します。これを用いて、ユニコード正規化によって2文字以上に展開される文字(合字や結合文字)を正規化の対象外とします。
- Pros
- ICU normalizer character filter が提供するオプションを使って素直に実現可能
- Cons
- 正規化対象外の文字がヒットしない
- 例えば、合字
㍻は正規化されずそのまま索引付けされるので、平成で検索してもヒットしません。
- 例えば、合字
- 正規化対象外の文字がヒットしない
3. Tokenizer の時点で、バグの原因となる文字が複数のトークンに分割されないように修正する
平成 などの正規化の後に分割されて欲しく無い単語を、ユーザ辞書に登録しておくなどの方法で分割されないように制御します。
- Pros
- ICU normalizer character filter を当初の期待通り適用できる
- Cons
4. Token Filter の時点で、Character Filter の代わりに後処理としてユニコード正規化を適用する
ICU normalization token filter という、トークン化の後に正規化を適用するオプションも用意されています。ICU normalizer character filter の代わりにこれを使用する方法です。
- Pros
- 導入が簡単
- Cons
- トークナイザーの解析結果に悪影響
- 正規化されていない文がトークナイズされるため、それによる悪影響が考えられます。例えば、日本語の形態素解析器で使用する辞書は、全ての表記揺れを登録していないことが多く、半角全角のような差異が検索結果に影響し得ます。
- Elasticsearch のドキュメントでも、トークナイズ前の正規化の適用が推奨されています。
- 引用1
To avoid this, add the icu_normalizer character filter to a custom analyzer based on the kuromoji analyzer. The icu_normalizer character filter converts full-width characters to their normal equivalents. https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-kuromoji-analyzer.html#kuromoji-analyzer-normalize-full-width-characters
- 引用2
You should probably prefer the Normalization character filter. https://www.elastic.co/guide/en/elasticsearch/plugins/current/analysis-icu-normalization.html
- 引用1
- トークナイザーの解析結果に悪影響
議論
- 1 の案は、Character Filter でユニコード正規化する場合と同じ検索精度を保証できます。しかし、あまりに管理コストが高く付きそうです。ユーザから見える表層に影響があるのも望ましくありません。今回のバグは頻発するものではないので、その対策としては少しドラスティックに思えます。
- 2 の案を採用するべきかは、正規化の対象外となる文字がどれくらいの割合で、どれくらい検索精度に影響があるかに依存します。影響が少ない場合は、ICU normalizer のオプションを使って素直に導入できますし、良い選択肢となり得るでしょう。
- 3 の案は、実現方法や実現可能性がトークナイザーに依存する点がネックです。また、トークナイザーごとに辞書の管理が必要となると、管理コストの増加も懸念されます。
- 4 の案は、トークナイザーの解析結果に悪影響がある点が望ましくないです。今回のバグは頻発するものではないので、全ての文字の正規化をしないというのは少しドラスティックに思えます。
2 の案に関する調査と具体的な対処方法
上の議論から、2 の案が最も導入や運用が簡単そうです。
この節では、2 の案でどのような文字が正規化の対象外となるか、検索結果への影響はありそうか、などを調査します。そして、具体的な実装方法を提供します。
対象外となる文字についての調査
全てのユニコード文字(コードポイント0x00 から 0x10FFFF まで)について、NFKC + Case Folding で複数文字に展開される文字を調査しました。1
その結果 1,114,112 文字中 1,326 文字が該当し、その割合は 0.12% でした。ユニコード文字全体に対しては、ごく一部が該当するようです。㌖ ㍿ ㈱ ㋉ ⑩ ㍢ などがその例です。これらを正規化の対象外としても、検索結果への影響は少なそうに思えます。2
具体的な Character Filter の設定
これらの文字を対象外とした ICU normalizer は、以下のように unicode_set_filter にパターンを定義すれば実現できます。
"char_filter": { "custom_icu_normalizer": { "type": "icu_normalizer", "name": "nfkc_cf", "unicode_set_filter": "[^\u00a8\u00af\u00b4\u00b8\u00bc\u00bd\u00be\u00df\u0130\u0132\u0133\u013f\u0140\u0149\u01c4\u01c5\u01c6\u01c7\u01c8\u01c9\u01ca\u01cb\u01cc\u01f0\u01f1\u01f2\u01f3\u02d8\u02d9\u02da\u02db\u02dc\u02dd\u0344\u037a\u0384\u0385\u0390\u03b0\u0587\u0675\u0676\u0677\u0678\u0958\u0959\u095a\u095b\u095c\u095d\u095e\u095f\u09dc\u09dd\u09df\u0a33\u0a36\u0a59\u0a5a\u0a5b\u0a5e\u0b5c\u0b5d\u0e33\u0eb3\u0edc\u0edd\u0f43\u0f4d\u0f52\u0f57\u0f5c\u0f69\u0f73\u0f75\u0f76\u0f77\u0f78\u0f79\u0f81\u0f93\u0f9d\u0fa2\u0fa7\u0fac\u0fb9\u1e96\u1e97\u1e98\u1e99\u1e9a\u1e9e\u1f50\u1f52\u1f54\u1f56\u1f80\u1f81\u1f82\u1f83\u1f84\u1f85\u1f86\u1f87\u1f88\u1f89\u1f8a\u1f8b\u1f8c\u1f8d\u1f8e\u1f8f\u1f90\u1f91\u1f92\u1f93\u1f94\u1f95\u1f96\u1f97\u1f98\u1f99\u1f9a\u1f9b\u1f9c\u1f9d\u1f9e\u1f9f\u1fa0\u1fa1\u1fa2\u1fa3\u1fa4\u1fa5\u1fa6\u1fa7\u1fa8\u1fa9\u1faa\u1fab\u1fac\u1fad\u1fae\u1faf\u1fb2\u1fb3\u1fb4\u1fb6\u1fb7\u1fbc\u1fbd\u1fbf\u1fc0\u1fc1\u1fc2\u1fc3\u1fc4\u1fc6\u1fc7\u1fcc\u1fcd\u1fce\u1fcf\u1fd2\u1fd3\u1fd6\u1fd7\u1fdd\u1fde\u1fdf\u1fe2\u1fe3\u1fe4\u1fe6\u1fe7\u1fed\u1fee\u1ff2\u1ff3\u1ff4\u1ff6\u1ff7\u1ffc\u1ffd\u1ffe\u2017\u2025\u2026\u2033\u2034\u2036\u2037\u203c\u203e\u2047\u2048\u2049\u2057\u20a8\u2100\u2101\u2103\u2105\u2106\u2109\u2116\u2120\u2121\u2122\u213b\u2150\u2151\u2152\u2153\u2154\u2155\u2156\u2157\u2158\u2159\u215a\u215b\u215c\u215d\u215e\u215f\u2161\u2162\u2163\u2165\u2166\u2167\u2168\u216a\u216b\u2171\u2172\u2173\u2175\u2176\u2177\u2178\u217a\u217b\u2189\u222c\u222d\u222f\u2230\u2469\u246a\u246b\u246c\u246d\u246e\u246f\u2470\u2471\u2472\u2473\u2474\u2475\u2476\u2477\u2478\u2479\u247a\u247b\u247c\u247d\u247e\u247f\u2480\u2481\u2482\u2483\u2484\u2485\u2486\u2487\u2488\u2489\u248a\u248b\u248c\u248d\u248e\u248f\u2490\u2491\u2492\u2493\u2494\u2495\u2496\u2497\u2498\u2499\u249a\u249b\u249c\u249d\u249e\u249f\u24a0\u24a1\u24a2\u24a3\u24a4\u24a5\u24a6\u24a7\u24a8\u24a9\u24aa\u24ab\u24ac\u24ad\u24ae\u24af\u24b0\u24b1\u24b2\u24b3\u24b4\u24b5\u2a0c\u2a74\u2a75\u2a76\u2adc\u309b\u309c\u309f\u30ff\u3200\u3201\u3202\u3203\u3204\u3205\u3206\u3207\u3208\u3209\u320a\u320b\u320c\u320d\u320e\u320f\u3210\u3211\u3212\u3213\u3214\u3215\u3216\u3217\u3218\u3219\u321a\u321b\u321c\u321d\u321e\u3220\u3221\u3222\u3223\u3224\u3225\u3226\u3227\u3228\u3229\u322a\u322b\u322c\u322d\u322e\u322f\u3230\u3231\u3232\u3233\u3234\u3235\u3236\u3237\u3238\u3239\u323a\u323b\u323c\u323d\u323e\u323f\u3240\u3241\u3242\u3243\u3250\u3251\u3252\u3253\u3254\u3255\u3256\u3257\u3258\u3259\u325a\u325b\u325c\u325d\u325e\u325f\u327c\u327d\u32b1\u32b2\u32b3\u32b4\u32b5\u32b6\u32b7\u32b8\u32b9\u32ba\u32bb\u32bc\u32bd\u32be\u32bf\u32c0\u32c1\u32c2\u32c3\u32c4\u32c5\u32c6\u32c7\u32c8\u32c9\u32ca\u32cb\u32cc\u32cd\u32ce\u32cf\u32ff\u3300\u3301\u3302\u3303\u3304\u3305\u3306\u3307\u3308\u3309\u330a\u330b\u330c\u330d\u330e\u330f\u3310\u3311\u3312\u3313\u3314\u3315\u3316\u3317\u3318\u3319\u331a\u331b\u331c\u331d\u331e\u331f\u3320\u3321\u3322\u3323\u3324\u3325\u3326\u3327\u3328\u3329\u332a\u332b\u332c\u332d\u332e\u332f\u3330\u3331\u3332\u3333\u3334\u3335\u3336\u3337\u3338\u3339\u333a\u333b\u333c\u333d\u333e\u333f\u3340\u3341\u3342\u3343\u3344\u3345\u3346\u3347\u3348\u3349\u334a\u334b\u334c\u334d\u334e\u334f\u3350\u3351\u3352\u3353\u3354\u3355\u3356\u3357\u3358\u3359\u335a\u335b\u335c\u335d\u335e\u335f\u3360\u3361\u3362\u3363\u3364\u3365\u3366\u3367\u3368\u3369\u336a\u336b\u336c\u336d\u336e\u336f\u3370\u3371\u3372\u3373\u3374\u3375\u3376\u3377\u3378\u3379\u337a\u337b\u337c\u337d\u337e\u337f\u3380\u3381\u3382\u3383\u3384\u3385\u3386\u3387\u3388\u3389\u338a\u338b\u338c\u338d\u338e\u338f\u3390\u3391\u3392\u3393\u3394\u3395\u3396\u3397\u3398\u3399\u339a\u339b\u339c\u339d\u339e\u339f\u33a0\u33a1\u33a2\u33a3\u33a4\u33a5\u33a6\u33a7\u33a8\u33a9\u33aa\u33ab\u33ac\u33ad\u33ae\u33af\u33b0\u33b1\u33b2\u33b3\u33b4\u33b5\u33b6\u33b7\u33b8\u33b9\u33ba\u33bb\u33bc\u33bd\u33be\u33bf\u33c0\u33c1\u33c2\u33c3\u33c4\u33c5\u33c6\u33c7\u33c8\u33c9\u33ca\u33cb\u33cc\u33cd\u33ce\u33cf\u33d0\u33d1\u33d2\u33d3\u33d4\u33d5\u33d6\u33d7\u33d8\u33d9\u33da\u33db\u33dc\u33dd\u33de\u33df\u33e0\u33e1\u33e2\u33e3\u33e4\u33e5\u33e6\u33e7\u33e8\u33e9\u33ea\u33eb\u33ec\u33ed\u33ee\u33ef\u33f0\u33f1\u33f2\u33f3\u33f4\u33f5\u33f6\u33f7\u33f8\u33f9\u33fa\u33fb\u33fc\u33fd\u33fe\u33ff\ufb00\ufb01\ufb02\ufb03\ufb04\ufb05\ufb06\ufb13\ufb14\ufb15\ufb16\ufb17\ufb1d\ufb1f\ufb2a\ufb2b\ufb2c\ufb2d\ufb2e\ufb2f\ufb30\ufb31\ufb32\ufb33\ufb34\ufb35\ufb36\ufb38\ufb39\ufb3a\ufb3b\ufb3c\ufb3e\ufb40\ufb41\ufb43\ufb44\ufb46\ufb47\ufb48\ufb49\ufb4a\ufb4b\ufb4c\ufb4d\ufb4e\ufb4f\ufbdd\ufbea\ufbeb\ufbec\ufbed\ufbee\ufbef\ufbf0\ufbf1\ufbf2\ufbf3\ufbf4\ufbf5\ufbf6\ufbf7\ufbf8\ufbf9\ufbfa\ufbfb\ufc00\ufc01\ufc02\ufc03\ufc04\ufc05\ufc06\ufc07\ufc08\ufc09\ufc0a\ufc0b\ufc0c\ufc0d\ufc0e\ufc0f\ufc10\ufc11\ufc12\ufc13\ufc14\ufc15\ufc16\ufc17\ufc18\ufc19\ufc1a\ufc1b\ufc1c\ufc1d\ufc1e\ufc1f\ufc20\ufc21\ufc22\ufc23\ufc24\ufc25\ufc26\ufc27\ufc28\ufc29\ufc2a\ufc2b\ufc2c\ufc2d\ufc2e\ufc2f\ufc30\ufc31\ufc32\ufc33\ufc34\ufc35\ufc36\ufc37\ufc38\ufc39\ufc3a\ufc3b\ufc3c\ufc3d\ufc3e\ufc3f\ufc40\ufc41\ufc42\ufc43\ufc44\ufc45\ufc46\ufc47\ufc48\ufc49\ufc4a\ufc4b\ufc4c\ufc4d\ufc4e\ufc4f\ufc50\ufc51\ufc52\ufc53\ufc54\ufc55\ufc56\ufc57\ufc58\ufc59\ufc5a\ufc5b\ufc5c\ufc5d\ufc5e\ufc5f\ufc60\ufc61\ufc62\ufc63\ufc64\ufc65\ufc66\ufc67\ufc68\ufc69\ufc6a\ufc6b\ufc6c\ufc6d\ufc6e\ufc6f\ufc70\ufc71\ufc72\ufc73\ufc74\ufc75\ufc76\ufc77\ufc78\ufc79\ufc7a\ufc7b\ufc7c\ufc7d\ufc7e\ufc7f\ufc80\ufc81\ufc82\ufc83\ufc84\ufc85\ufc86\ufc87\ufc88\ufc89\ufc8a\ufc8b\ufc8c\ufc8d\ufc8e\ufc8f\ufc90\ufc91\ufc92\ufc93\ufc94\ufc95\ufc96\ufc97\ufc98\ufc99\ufc9a\ufc9b\ufc9c\ufc9d\ufc9e\ufc9f\ufca0\ufca1\ufca2\ufca3\ufca4\ufca5\ufca6\ufca7\ufca8\ufca9\ufcaa\ufcab\ufcac\ufcad\ufcae\ufcaf\ufcb0\ufcb1\ufcb2\ufcb3\ufcb4\ufcb5\ufcb6\ufcb7\ufcb8\ufcb9\ufcba\ufcbb\ufcbc\ufcbd\ufcbe\ufcbf\ufcc0\ufcc1\ufcc2\ufcc3\ufcc4\ufcc5\ufcc6\ufcc7\ufcc8\ufcc9\ufcca\ufccb\ufccc\ufccd\ufcce\ufccf\ufcd0\ufcd1\ufcd2\ufcd3\ufcd4\ufcd5\ufcd6\ufcd7\ufcd8\ufcd9\ufcda\ufcdb\ufcdc\ufcdd\ufcde\ufcdf\ufce0\ufce1\ufce2\ufce3\ufce4\ufce5\ufce6\ufce7\ufce8\ufce9\ufcea\ufceb\ufcec\ufced\ufcee\ufcef\ufcf0\ufcf1\ufcf2\ufcf3\ufcf4\ufcf5\ufcf6\ufcf7\ufcf8\ufcf9\ufcfa\ufcfb\ufcfc\ufcfd\ufcfe\ufcff\ufd00\ufd01\ufd02\ufd03\ufd04\ufd05\ufd06\ufd07\ufd08\ufd09\ufd0a\ufd0b\ufd0c\ufd0d\ufd0e\ufd0f\ufd10\ufd11\ufd12\ufd13\ufd14\ufd15\ufd16\ufd17\ufd18\ufd19\ufd1a\ufd1b\ufd1c\ufd1d\ufd1e\ufd1f\ufd20\ufd21\ufd22\ufd23\ufd24\ufd25\ufd26\ufd27\ufd28\ufd29\ufd2a\ufd2b\ufd2c\ufd2d\ufd2e\ufd2f\ufd30\ufd31\ufd32\ufd33\ufd34\ufd35\ufd36\ufd37\ufd38\ufd39\ufd3a\ufd3b\ufd3c\ufd3d\ufd50\ufd51\ufd52\ufd53\ufd54\ufd55\ufd56\ufd57\ufd58\ufd59\ufd5a\ufd5b\ufd5c\ufd5d\ufd5e\ufd5f\ufd60\ufd61\ufd62\ufd63\ufd64\ufd65\ufd66\ufd67\ufd68\ufd69\ufd6a\ufd6b\ufd6c\ufd6d\ufd6e\ufd6f\ufd70\ufd71\ufd72\ufd73\ufd74\ufd75\ufd76\ufd77\ufd78\ufd79\ufd7a\ufd7b\ufd7c\ufd7d\ufd7e\ufd7f\ufd80\ufd81\ufd82\ufd83\ufd84\ufd85\ufd86\ufd87\ufd88\ufd89\ufd8a\ufd8b\ufd8c\ufd8d\ufd8e\ufd8f\ufd92\ufd93\ufd94\ufd95\ufd96\ufd97\ufd98\ufd99\ufd9a\ufd9b\ufd9c\ufd9d\ufd9e\ufd9f\ufda0\ufda1\ufda2\ufda3\ufda4\ufda5\ufda6\ufda7\ufda8\ufda9\ufdaa\ufdab\ufdac\ufdad\ufdae\ufdaf\ufdb0\ufdb1\ufdb2\ufdb3\ufdb4\ufdb5\ufdb6\ufdb7\ufdb8\ufdb9\ufdba\ufdbb\ufdbc\ufdbd\ufdbe\ufdbf\ufdc0\ufdc1\ufdc2\ufdc3\ufdc4\ufdc5\ufdc6\ufdc7\ufdf0\ufdf1\ufdf2\ufdf3\ufdf4\ufdf5\ufdf6\ufdf7\ufdf8\ufdf9\ufdfa\ufdfb\ufdfc\ufe19\ufe30\ufe49\ufe4a\ufe4b\ufe4c\ufe70\ufe71\ufe72\ufe74\ufe76\ufe77\ufe78\ufe79\ufe7a\ufe7b\ufe7c\ufe7d\ufe7e\ufe7f\ufef5\ufef6\ufef7\ufef8\ufef9\ufefa\ufefb\ufefc\uffe3\ud834\udd5e\ud834\udd5f\ud834\udd60\ud834\udd61\ud834\udd62\ud834\udd63\ud834\udd64\ud834\uddbb\ud834\uddbc\ud834\uddbd\ud834\uddbe\ud834\uddbf\ud834\uddc0\ud83c\udd00\ud83c\udd01\ud83c\udd02\ud83c\udd03\ud83c\udd04\ud83c\udd05\ud83c\udd06\ud83c\udd07\ud83c\udd08\ud83c\udd09\ud83c\udd0a\ud83c\udd10\ud83c\udd11\ud83c\udd12\ud83c\udd13\ud83c\udd14\ud83c\udd15\ud83c\udd16\ud83c\udd17\ud83c\udd18\ud83c\udd19\ud83c\udd1a\ud83c\udd1b\ud83c\udd1c\ud83c\udd1d\ud83c\udd1e\ud83c\udd1f\ud83c\udd20\ud83c\udd21\ud83c\udd22\ud83c\udd23\ud83c\udd24\ud83c\udd25\ud83c\udd26\ud83c\udd27\ud83c\udd28\ud83c\udd29\ud83c\udd2a\ud83c\udd2d\ud83c\udd2e\ud83c\udd4a\ud83c\udd4b\ud83c\udd4c\ud83c\udd4d\ud83c\udd4e\ud83c\udd4f\ud83c\udd6a\ud83c\udd6b\ud83c\udd6c\ud83c\udd90\ud83c\ude00\ud83c\ude01\ud83c\ude40\ud83c\ude41\ud83c\ude42\ud83c\ude43\ud83c\ude44\ud83c\ude45\ud83c\ude46\ud83c\ude47\ud83c\ude48]" } }
この custom_icu_normalizer を icu_normalizer の代わりに使用すれば、本記事で報告したバグは一旦回避できます。
ただし、このパターンは ICU normalizer のデフォルトオプションである NFKC + Case Folding についてのパターンであることに注意してください。別の正規化オプションを使用する場合は、それに応じたパターンが必要です。以下にオプションに応じてパターンを出力するスクリプトを用意したので、必要に応じて使用してください。
import sys import unicodedata from typing import Literal def icu_normalize( text: str, name: Literal["nfc", "nfkc", "nfkc_cf"] = "nfkc_cf", mode: Literal["compose", "decompose"] = "compose", ) -> str: if name == "nfc" and mode == "compose": return unicodedata.normalize("NFC", text) elif name == "nfc" and mode == "decompose": return unicodedata.normalize("NFD", text) elif name == "nfkc" and mode == "compose": return unicodedata.normalize("NFKC", text) elif name == "nfkc" and mode == "decompose": return unicodedata.normalize("NFKD", text) elif name == "nfkc_cf" and mode == "compose": return unicodedata.normalize("NFKC", text).casefold() elif name == "nfkc_cf" and mode == "decompose": return unicodedata.normalize("NFKD", text).casefold() else: raise RuntimeError("Should not reach here") def point_to_unit(i: int) -> str: if i < 0x10000: return f"\\u{i:04x}" else: # Surrogate pair i -= 0x10000 high = 0xD800 + (i >> 10) low = 0xDC00 + (i & 0x3FF) return f"\\u{high:04x}\\u{low:04x}" def generate_pattern(codepoints: list[int]) -> str: codeunits = [point_to_unit(codepoint) for codepoint in codepoints] return f"[^{''.join(codeunits)}]" if __name__ == "__main__": target_codepoints = [] for codepoint in range(sys.maxunicode + 1): character = chr(codepoint) # Edit the normalization options as you like. normalized = icu_normalize(text=character, name="nfkc_cf", mode="compose") if len(normalized) > 1: target_codepoints.append(codepoint) print(generate_pattern(target_codepoints)) n_targets = len(target_codepoints) n_unichars = sys.maxunicode + 1 p_targets = n_targets / n_unichars * 100 print(f"Found {n_targets}/{n_unichars} targets ({p_targets:.2f}%)")
おわりに
本記事では、Lucene/Elasticsearch でユニコード正規化した際に発生するバグについて説明し、その Workaround を提示しました。
頻発するバグでは無いものの、エラーが発生する以上目を瞑るわけにもいかず、最小限の工数コストで対処したい案件だったと思います。もしお手元の環境で同じような現象に直面したときに、この記事が助けになれば幸いです。
メンバー募集中!!
株式会社LegalOn Technologies では、検索エンジニアやMLエンジニアなど、複数のポジションでエンジニアを募集しています。気軽にご応募ください。