はじめに
こんにちは。株式会社LegalOn Technologies でエンジニアをしております、勝田(@WinField95)です。この記事は、情報検索・検索技術 Advent Calendar 2023 の 20日目の記事として執筆されました。
この記事では、ANTLR[1]を使用したシンプルなクエリ構文の解析を行う検索クエリパーサーの生成と、解析結果から Elasticsearch の Query DSL[2]への変換までのプロセスと簡単な実装を紹介します。実務では、要求に応じて複雑なクエリ構文の文法定義が必要になる場合もありますが、この記事ではなるべく簡単なクエリ構文を取り扱います。解説で使用するコードは、この GitHub のリポジトリで公開しますので、参考にしてみてください。また、Search Engineering Tech Talk 2023 Winter では、この記事の内容をもとに発表を行いました。ぜひスライドもご覧ください。
[1] ANTLR
[2] Query DSL | Elasticsearch Guide [8.11]
目次
モチベーション
検索クエリパーサーを自作する必要性
複雑なクエリ構文に対応した検索システムを開発する際には、検索クエリパーサーを自作することが有力な選択肢となるかもしれません。検索システムでは、ユーザーがテキストボックスに入力した検索クエリを実行します。論理演算子や括弧による演算順序の指定に対応したクエリ構文が定義されている場合は、より柔軟な検索が可能になります。Elasticsearchでは Query string query [3] や Simple query string query [4] にてクエリ構文が提供されていますが、これらの方法は不特定多数のユーザーに使用されることに適さなかったり、クエリ構文の表現が固定されていたりすることで、利用が難しい場合があります。さらに、以下のように検索システムの要求や検索挙動の改善を考慮する場合、自由に拡張可能な検索クエリパーサーを自作することが妥当かもしれません。
独自の演算子表現の定義
ANDや&といった表現をAND演算子として扱いたいなど、表現の変更に対して柔軟に対応したい場合があります。検索クエリパーサーを使用すれば、クエリ内の演算子を特定し、検索エンジンが解釈可能な表現に変換できます。Query Understanding のための処理の実行
Query Understanding [5] は検索体験を向上させるテクニックで、検索システムが検索者の意図を解釈するプロセスを含みます。Semantic Analysis のため、Query Classification や Query Segmentation、Tagging などの処理の実行、あるいはスペル修正などの Query Reformulation が必要な場合があります。構文解析によりクエリ内の語句を特定できるため、クエリ構文をサポートしつつ、クエリ内の語句を活用した処理の実行やクエリの再構築が可能になります。
語句に対する検索フィールドの指定
後に詳しく述べますが、Query string query では、語句に対する検索フィールドの指定にセキュリティリスクが存在し、一方で Simple query string query では、語句に対する検索フィールドの指定ができないといった問題があります。これらの問題は、構文解析によって語句に対する検索フィールド部分を把握し、あらかじめ検索対象となっている検索フィールドかどうかを判定する処理を加えることでセキュリティリスクを抑えることができます。
[3] Query string query | Elasticsearch Guide [8.11]
[4] Simple query string query | Elasticsearch Guide [8.11]
[5] Query Understanding for Search Engines Chapter 1 An Introduction to Query Understanding
Elasticsearch の Query string query と Simple query sting query について
Elasticsearchは、Query string query や Simple query string query という機能を提供しています。先ほど、これらの利用に苦労する点について簡単に触れましたが、ここではその詳細を解説します。
Query string query
AND、OR、NOT などの演算子、括弧によるネストの解釈、検索キーワードに対する検索フィールドの指定などのクエリ構文が使用できます。さらに、ワイルドカードや正規表現の指定も可能で、多機能なものとなります。
しかし、不特定多数のユーザーが触れるようなサービスでの利用には適していない側面があります。例えば、fieldsで指定されたフィールド以外の検索フィールドも、クエリ内の語句に直接フィールド名を指定することで、検索対象とすることが可能となります[6]。 これは本来検索対象としたくないフィールドへの検索が可能となり、セキュリティリスクがあります。また、単語の先頭にワイルドカードを許可すると、クエリの実行速度が極端に低下するリスクがあります[7]。 さらに、無効な構文に対しては検索が実行されずにエラーが返されるため、Query string query を検索ボックスで使用すること自体が推奨されていません[8]。 便利ではありますが、不特定多数のユーザーが利用するようなサービスでの使用は難しいかもしれません。
[6] 検索システム ― 実務者のための開発改善ガイドブック 第6章 検索インターフェースと検索クエリの処理 6.7.4 検索対象の限定
[7] Query string query Wildcards の WARNING
[8] Query string query WARNING
Simple query string query
Query string query と比較して、構文には制約がありますが、基本的なクエリ構文を使用することが可能です。無効なクエリ構文に対してエラーを返さない性質や、fieldsで指定されたフィールド以外を検索できないという点は、Query string query よりも不特定多数のユーザーが触れるような検索システムの利用に適しているかもしれません。
一方で、AND 演算子 は +、OR 演算子 は、|、NOT 演算子は-といったように、演算子の表現は予め決められています[9]。 これ以外の演算子を用いたい場合には変換処理の実装が必要となります。また、Query string query では、語句の接頭辞に検索フィールドを指定することで特定のフィールドに絞った検索ができますが、Simple query string queryではこのような指定方法はできません。
無効なクエリ構文に対してエラーを返さない性質について
例えば、
AAA OR BBB ORのようなクエリ構文に従わない検索クエリで Query string query を実行すると、エラーが返されます。しかし、Simple query string query では、AAA | BBB |のような検索クエリを実行してもエラーは発生せず、検索が行われます。このように、Simple query string queryは、クエリ構文の誤りなどのヒューマンエラーに対して柔軟に対応できます。fieldsで指定されたフィールド以外は検索できないという点について
例えば、Query string query では、以下の Query DSL のように fields で fruit というフィールド名を指定していても、query で
production_area:domesticのように別のフィールド名を prefix として指定すると、そのフィールドも検索対象になってしまいます。しかし、Simple query string queryでは、fields で指定したフィールドだけが検索対象となります。このように、Simple query string queryは、想定外の検索フィールドをユーザーから指定されることはなく、Query string query が引き起こすセキュリティリスクを解消することができます。
{ "query": { "query_string" : { "query": "production_area:domestic", "fields": ["fruit"], "default_operator": "and" } } }
[9] Simple query string syntax
課題設定と実装方針
検索クエリパーサー自作のための課題設定
検索クエリとして与えられる文字列をクエリ構文の文法に基づいて解析を行い、Query DSL を構築することを課題とします。 fruit_basket という名前の Index を Elasticsearch に用意し、fruit_basket には、下記のような fruit というフィールドの値がそれぞれ apple, orange, banana であるドキュメントを格納します。例えば、(apple OR orange) AND NOT bananaという検索クエリが与えられた場合に、apple と orange がヒットされるような、Query DSL を構築することを目指します。
curl -XPUT localhost:9200/fruit_basket/_create/1 -H "Content-Type: application/json" -d '{ "fruit": "orange" }'; curl -XPUT localhost:9200/fruit_basket/_create/2 -H "Content-Type: application/json" -d '{ "fruit": "apple" }'; curl -XPUT localhost:9200/fruit_basket/_create/3 -H "Content-Type: application/json" -d '{ "fruit": "banana" }';
クエリ構文の仕様
今回定義するクエリ構文は下記のようなシンプルなものとします。
Conjunctive query
A AND Bで検索すると、AとBをどちらも含む文書のみがヒットする。Disjunctive query
A OR Bで検索すると、AとBのどちらか一方でも含む文書がヒットする。Negative query
NOT Aで検索すると、Aを含まない文書のみがヒットする。Compound query
Conjunctive query、Disjunctive query、Negative query を複数組み合わせたクエリ。
実装方針
実現したいことは、検索クエリとして与えられた文字列を適切な Query DSL に変換することです。これはプログラミング言語のコンパイルに似た処理です。一般的なコンパイラは、字句解析、構文解析、意味解析を経て、中間表現に翻訳され、その後、最終的なコードが生成されます[10]。(実際にはさらに詳細な工程がありますが、この記事では省略しています。)
一般的なコンパイラの処理の流れ (最新コンパイラ構成技法 より一部引用)
ソースプログラム (INPUT) ↓ 字句解析 (ソースファイルを、個々の単語あるいはトークンへと分解する。) ↓ 構文解析 (プログラムの句構造を構文解析する。) ↓ 意味解析 (変数の使用をその定義に関連付け、式の型を検査して各句の意味を決定した上で、各句の翻訳を要求する。) ↓ 翻訳 (特定のプログラミング言語や目的のマシンのアーキテクチャに束縛されない中間表現を生成する。) ↓ 最適化 (中間表現をより効率の良い内容に変換をする。) ↓ コード生成 ↓ ターゲットプログラム (OUTPUT)
今回の場合、特に意味解析や最適化を考慮しないとした場合、以下の構造が妥当と思われます。
検索クエリ変換処理の流れ
検索クエリ (INPUT) ↓ 字句解析 (検索クエリを、個々の単語あるいはトークンへと分解する。) ↓ 構文解析 (検索クエリの句構造を構文解析する。) ↓ 翻訳 (特定の検索エンジンに束縛されない中間表現を生成する。) ↓ コード生成 (Query DSL を生成する。) ↓ Elasticsearch Query DSL (OUTPUT)
この記事では、検索クエリを字句解析と構文解析を行って抽象構文木に変換する処理を Query Parser とし、抽象構文木から検索エンジンのクエリを生成する処理を Query Builder とします。 抽象構文木とは、構文解析器から出力される構文木から、言語の意味に関係のない部分を取り除き抽象化した木構造のことを指します。今回は、この抽象構文木を中間表現として利用します。

[10] 最新コンパイラ構成技法 第1章 はじめに 1.1 モジュールとインターフェイス
パーサジェネレータの導入
構文解析とは、形式的に与えられた文法に従って文字列を分析する手続きです。 構文解析器の実装はかなりの労力を必要とします。そのため、構文解析器を自動生成するプログラムであるパーサジェネレータを活用することをお勧めします。今回は、ANTLR というパーサジェネレータを使用してみます。
ANTLRの概要
ANTLR は、プログラミング言語の処理系の開発などに幅広く使われている強力なパーサジェネレータです。ANTLR を使用することで、特定の言語の構文を解析し、その構文木を生成するための字句解析器と構文解析器を手軽に生成することができます。また、Visitor と Listener と呼ばれる構文木を走査するためのプログラムの生成もでき、これらの字句解析器や構文解析器、 Visitor、 Listener は、C++, Java, Python, Go などの様々なプログラミング言語の形式での出力に対応しています。
字句解析器(Lexer)は文字列を解析し、トークン(言語の最小単位)に分けます。次に、構文解析器(Parser)がこれらのトークン列を解析して構文木を生成します[11]。この字句解析器と構文解析器の生成には、文法を記述した grammar ファイルが必要です。
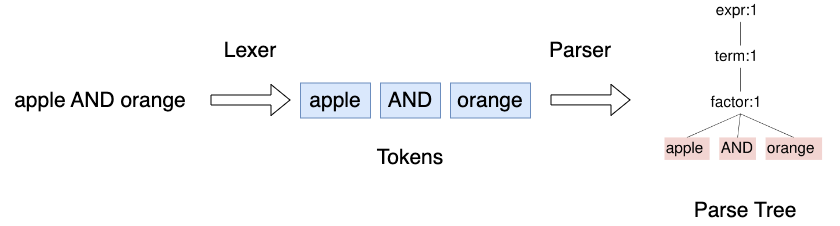
Visitor や Listener は、構文木の各ノードを一度だけ訪問する走査を行います。例えば、Visitor は post-order で各ノードを巡ります[12]。 post-order は、下記の図に示されているように、ノードの左のサブツリーを再帰的に走査した後、右のサブツリーを再帰的に走査し、その後で現在のノードを訪問するという手順で巡回します。また、各ノードで計算を実行し、結果を親ノードに伝達することで、式の計算やデータ構造の構築をしたり、不要なノードを除去して抽象構文木を生成することができます。
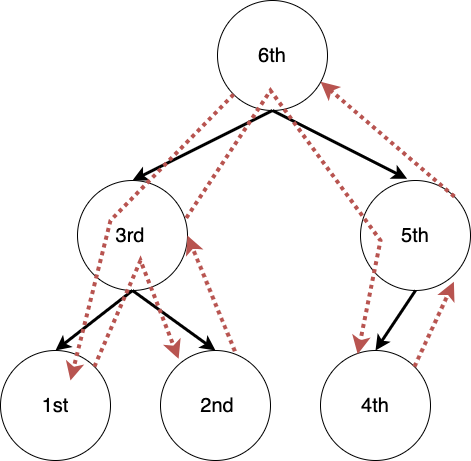
[11] The ANTLR Mega Tutorial Beginner 6. Lexers and Parsers
[12] antlr4/doc/python-target.md Visitors
環境構築
早速ですが、ANTLRをローカルで利用するための環境を整備しましょう。ローカルで手軽に利用するためには、antlr4-tools のインストールが便利です。また、Python3 で Parser を動かすために、antlr4-python3-runtime もインストールします。
以下のコマンドでインストールします。
$ pip install antlr4-tools $ pip install antlr4-python3-runtime
VSCode のユーザーであれば、ANTLR4 grammar syntax support という拡張機能を追加すると便利です。この拡張機能は、ANTLR の grammars ファイルに対するシンタックスハイライト、コード補完機能、構文の可視化などの機能を提供します。この記事では、ANTLR4 grammar syntax support を利用しながら解説を進めていきます。
QueryParser の生成と抽象構文木の構築
クエリ構文の文法の記述
先ほど定義したクエリ構文を、BNF 記法で文法を定義します。 BNF 記法は、文脈自由文法を定義するための言語です。例えば、以下のように文法を定義します。
<or_operator>::= OR <and_operator>::= AND <not_operator>::= NOT <expr>::= <term>|<expr><or_operator><term> <term>::= <factor>|<term><and_operator><factor> <factor>::= <keyword>|<not_operator><keyword> <keyword>::= (<expr>)|<alphabets> <alphabets>::= a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z
この文法の定義は、演算子の優先順位を反映しています。つまり、NOT 演算子は AND 演算子よりも、 AND 演算子は OR 演算子よりも優先度が高いということを示しています。文法はなるべく優先度が高い演算子から処理されるように組まれています。
ANTLRの実行と構文木の可視化
BNF 記法で記した文法に基づき、VSCode の ANTLR4 grammar syntax support を用いた構文解析器の実行と可視化をしてみます。
まずは、下記のファイル構成で、.vscode/launch.json, src/SimpleSearchQuery.g4, src/input.txt を用意します。
.
|-- .vscode
| `-- launch.json
`-- src
|-- SimpleSearchQuery.g4
`-- input.txt
{ "version": "2.0.0", "configurations": [ { "name": "Debug ANTLR4 grammar", "type": "antlr-debug", "request": "launch", "input": "src/input.txt", "grammar": "src/SimpleSearchQuery.g4", "startRule": "expr", "printParseTree": true, "visualParseTree": true, } ] }
src/SimpleSearchQuery.g4
grammar SimpleSearchQuery;
/**
* parser
*/
expr: term | expr OR_OPERATOR term;
term: factor | term AND_OPERATOR factor;
factor: keywords | NOT_OPERATOR keywords;
keywords: '(' expr ')' | alphabets;
alphabets: ALPHABETS;
/**
* lexer
*/
ALPHABETS: [a-z]+ ;
OR_OPERATOR : 'OR';
AND_OPERATOR : 'AND';
NOT_OPERATOR : 'NOT';
WHITE_SPACES : [ \t\n\r]+ -> skip ;
src/input.txt
(apple OR orange) AND NOT banana
VSCodeの「デバッグの開始」を使って実行してみましょう。 これにより、以下のように構文木が可視化されます。 src/input.txt で定義した検索クエリが grammar ファイルで定義した文法に従って解析できていることが確認できます。
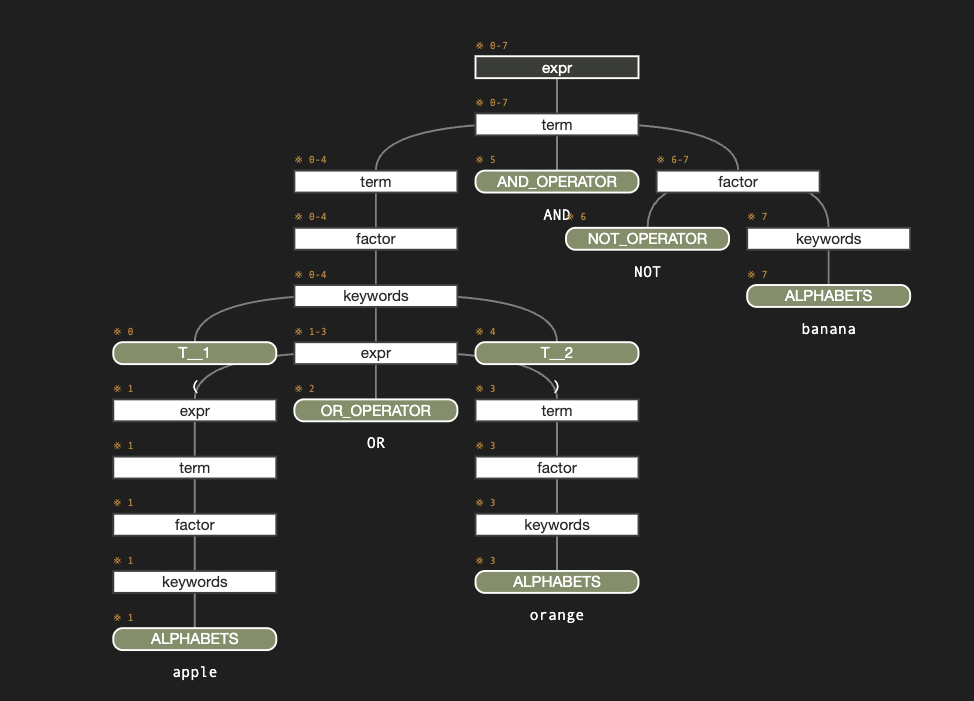
QueryParser の生成と抽象構文木の構築
可視化した構文木には、関係のないノードや不必要なノードがいくつか見られます。これらを省略し、構文木を抽象化したものを抽象構文木と言います。先ほどの構文木は、次のような抽象構文木に変換できます。
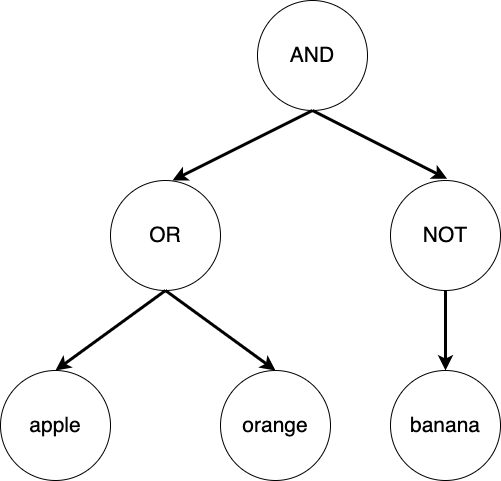
それでは、抽象構文木を構築してみましょう。
構文解析器などのコード生成のために、.vscode/settings.jsonを追加します。
{ "antlr4.generation":{ "mode": "external", "language": "Python3", "listeners": false, "visitors": true, "outputDir": "parser", } }
再度 src/SimpleSearchQuery.g4 を保存すると、src/parser というディレクトリが生成されます。
.
|-- .vscode
| |-- launch.json
| `-- settings.json
`-- src
|-- SimpleSearchQuery.g4
|-- input.txt
`-- parser
|-- SimpleSearchQuery.tokens
|-- SimpleSearchQueryLexer.py
|-- SimpleSearchQueryLexer.tokens
|-- SimpleSearchQueryParser.py
`-- SimpleSearchQueryVisitor.py
src/parser ディレクトリの中に src/SimpleSearchQueryLexer.py(字句解析器)、src/SimpleSearchQueryParser.py(構文解析器)、src/SimpleSearchQueryVisitor.py(Visitor)が存在します。これらを使用して、抽象構文木の構築コードを作成します。
以下のファイルについては自分で実装します。内容は、antlr4/doc/python-target.md のサンプルを参考にしています。
src/Driver1.py
src/input.txt を開いた後、Lexer や Parser の作成を行います。その後、Parser を呼び出します。
src/VisitorInterp.py
ノードを post-order で訪れる際、ボトムアップで抽象構文木を構築する実装を行います。 今回は、src/parser/SimpleSearchQueryVisitor.pyという Visitor が生成されます。したがって、SimpleSearchQueryVisitor を継承したVisitorInterp というクラスを定義し、その中で visit メソッドの実装を行います。
src/Driver1.py
import sys from antlr4 import CommonTokenStream, FileStream from src.parser.SimpleSearchQueryLexer import SimpleSearchQueryLexer from src.parser.SimpleSearchQueryParser import SimpleSearchQueryParser from src.VisitorInterp import VisitorInterp def main(argv): input_stream = FileStream(argv[1]) lexer = SimpleSearchQueryLexer(input_stream) stream = CommonTokenStream(lexer) parser = SimpleSearchQueryParser(stream) tree = parser.expr() if parser.getNumberOfSyntaxErrors() > 0: print("syntax errors") else: vinterp = VisitorInterp() print(vinterp.visit(tree)) if __name__ == "__main__": main(sys.argv)
src/VisitorInterp.py
from src.parser.SimpleSearchQueryParser import SimpleSearchQueryParser from src.parser.SimpleSearchQueryVisitor import SimpleSearchQueryVisitor class VisitorInterp(SimpleSearchQueryVisitor): def visitExpr(self, ctx: SimpleSearchQueryParser.ExprContext): if ctx.getChildCount() == 3: opc = ctx.getChild(1).getText() v1 = self.visit(ctx.getChild(0)) v2 = self.visit(ctx.getChild(2)) return {"operator": opc, "children": [v1, v2]} else: return self.visit(ctx.getChild(0)) def visitTerm(self, ctx: SimpleSearchQueryParser.TermContext): if ctx.getChildCount() == 3: opc = ctx.getChild(1).getText() v1 = self.visit(ctx.getChild(0)) v2 = self.visit(ctx.getChild(2)) return {"operator": opc, "children": [v1, v2]} else: return self.visit(ctx.getChild(0)) def visitFactor(self, ctx: SimpleSearchQueryParser.FactorContext): if ctx.getChildCount() == 2: opc = ctx.getChild(0).getText() v1 = self.visit(ctx.getChild(1)) return {"operator": opc, "children": [v1]} else: return self.visit(ctx.getChild(0)) def visitKeywords(self, ctx: SimpleSearchQueryParser.KeywordsContext): if ctx.getChildCount() == 3: return self.visit(ctx.getChild(1)) else: return self.visit(ctx.getChild(0)) def visitAlphabets(self, ctx: SimpleSearchQueryParser.AlphabetsContext): return {"value": ctx.getText()}
src/Driver1.py の 実行結果
$ python3 -m src.Driver1 ./src/input.txt {'operator': 'AND', 'children': [{'operator': 'OR', 'children': [{'value': 'apple'}, {'value': 'orange'}]}, {'operator': 'NOT', 'children': [{'value': 'banana'}]}]}
辞書型で表現された抽象構文木が得られましたね! 🎉
QueryBuilderの実装と実行
QueryBuilderの実装
抽象構文木から Elasticsearch Query DSL を構築します。 抽象構文木を走査し、ボトムアップな手順でクエリの構築を行う、QueryBuilder を実装してみましょう。
まず、抽象構文木の中間ノードにあたるクエリ構文の演算子を Elasticsearch の Boolean Query [13]に対応付けを試みます。
[13] Boolean query | Elasticsearch Guide [8.11]
OR 演算子への対応
{ "bool" : { "should" : [ ... ], "minimum_should_match" : 1, }, }AND 演算子への対応
{ "bool" : { "must" : [ ... ] } }NOT 演算子への対応
{ "bool" : { "must_not" : [ ... ] } }
抽象構文木の葉ノードには、トークンが該当するため、そのトークンを使用した Match query [14] を適用してみます。
トークンへの対応
{ "match": { "fruit": { "apple" } } }
[14] Match query | Elasticsearch Guide [8.11]
QueryBuilder では、抽象構文木を走査しながら、Elasticsearch Query DSL をボトムアップで構築する処理を行います。具体的な実装例は以下の通りです。
src/QueryBuilder.py
class QueryBuilder: def build(self, ast: dict) -> dict: return {"query": self.build_bool_query(ast)} def build_bool_query(self, ast: dict) -> dict: operator = ast.get("operator") if operator: match operator: case "AND": return { "bool": { "must": [ self.build_bool_query(ast["children"][0]), self.build_bool_query(ast["children"][1]), ] } } case "OR": return { "bool": { "should": [ self.build_bool_query(ast["children"][0]), self.build_bool_query(ast["children"][1]), ], "minimum_should_match": 1, }, } case "NOT": return { "bool": { "must_not": [ self.build_bool_query(ast["children"][0]), ], } } else: return { "match": { "fruit": { "query": ast["value"], } } }
Elasticsearch Query DSL の生成
src/QueryBuilder.py を src/Driver2.py で使用し、作成した Query DSL を出力します。 src/Driver2.py は、src/Driver1.py を拡張した内容となります。
parser/Driver2.py
import json import sys from antlr4 import CommonTokenStream, FileStream from src.parser.SimpleSearchQueryLexer import SimpleSearchQueryLexer from src.parser.SimpleSearchQueryParser import SimpleSearchQueryParser from src.QueryBuilder import QueryBuilder from src.VisitorInterp import VisitorInterp def main(argv): input_stream = FileStream(argv[1]) lexer = SimpleSearchQueryLexer(input_stream) stream = CommonTokenStream(lexer) parser = SimpleSearchQueryParser(stream) tree = parser.expr() if parser.getNumberOfSyntaxErrors() > 0: print("syntax errors") else: vinterp = VisitorInterp() query_builder = QueryBuilder() ast = vinterp.visit(tree) es_query = query_builder.build(ast) print(json.dumps(es_query)) if __name__ == "__main__": main(sys.argv)
それでは、QueryBuilder を取り込んだ src/Driver2.py を実行してみましょう!
QueryBuilder 実行
python3 -m src.Driver2 ./src/input.txt | jq { "query": { "bool": { "must": [ { "bool": { "must_not": [ { "match": { "fruit": { "query": "banana" } } } ] } }, { "bool": { "should": [ { "match": { "fruit": { "query": "orange" } } }, { "match": { "fruit": { "query": "apple" } } } ], "minimum_should_match": 1 } } ] } } }
抽象構文木に対応した Query DSL が得られましたね! 🎊
生成された Query DSL を用いた検索の実行と確認
実際に、QueryBuilder から生成された Query DSL を用いて検索を実行し、意図した検索挙動になっているか確認しましょう。先ほど実装した QueryParser と QueryBuilder を用いて、Elasticsearch への検索を実行する src/Searcher.py と、src/Searcher.py を扱う src/Driver3.py を実装します。
src/Searcher.py
from antlr4 import CommonTokenStream, InputStream from elasticsearch import Elasticsearch from src.parser.SimpleSearchQueryLexer import SimpleSearchQueryLexer from src.parser.SimpleSearchQueryParser import SimpleSearchQueryParser from src.QueryBuilder import QueryBuilder from src.VisitorInterp import VisitorInterp class Searcher: def __init__( self, endpoint: str = "http://localhost:9200", index: str = "fruit_basket" ): self.es_client = Elasticsearch([endpoint]) self.index = index self.vinterp = VisitorInterp() self.query_builder = QueryBuilder() def search(self, search_query: str) -> dict: input_stream = InputStream(search_query) lexer = SimpleSearchQueryLexer(input_stream) stream = CommonTokenStream(lexer) parser = SimpleSearchQueryParser(stream) tree = parser.expr() if parser.getNumberOfSyntaxErrors() > 0: raise ValueError("syntax errors") else: ast = self.vinterp.visit(tree) es_query = self.query_builder.build(ast) return self.es_client.search( index=self.index, **es_query, ).body
src/Driver3.py
import json import sys from src.Searcher import Searcher if __name__ == "__main__": argv = sys.argv input_filename = argv[1] with open(input_filename) as f: search_query = f.readline() searcher = Searcher() result = searcher.search(search_query) print(json.dumps(result))
src/Driver3.py による検索の実行
python3 -m src.Driver3 ./src/input.txt | jq { "took": 3, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 2, "relation": "eq" }, "max_score": 0.9808291, "hits": [ { "_index": "fruit_basket", "_id": "1", "_score": 0.9808291, "_source": { "fruit": "orange" } }, { "_index": "fruit_basket", "_id": "2", "_score": 0.9808291, "_source": { "fruit": "apple" } } ] } }
(apple OR orange) AND NOT banana の条件に当てはまる結果が得られました! 🥳
まとめ
今回は、検索クエリパーサーの自作のモチベーションから始め、ANTLR というパーサジェネレータを使用したクエリ構文を解析する検索クエリパーサーの作成、解析結果から抽象構文木への変換、そして抽象構文木から Elasticsearch の Query DSL の生成と実行までを説明しました。ANTLR を使用しましたが、字句・構文解析ライブラリは他にも多く存在します。例えば Python では、 Lark や pyparsing などがあります。サービスの要求や要件に応じて適切な字句・構文解析ライブラリを選択することをおすすめします。皆様が検索サービスの検索クエリパーサーを作成する際に参考にしていただければ幸いです。
メンバー募集中!!
株式会社LegalOn Technologies では、検索エンジニアも募集しています!気軽にご応募ください!
TECH-S-101- Software Engineer - Search - 株式会社LegalOn Technologies
TECH-S-102- Senior Software Engineer - Search - 株式会社LegalOn Technologies
参考
- 最新コンパイラ構成技法
- 検索システム ― 実務者のための開発改善ガイドブック
- Query Understanding for Search Engines
- Query DSL | Elasticsearch Guide [8.11]
- Query string query | Elasticsearch Guide [8.11]
- Simple query string query | Elasticsearch Guide [8.11]
- Boolean query | Elasticsearch Guide [8.11]
- Match query | Elasticsearch Guide [8.11]
- ANTLR
- ANTLR4 grammar syntax support
- antlr4/doc/python-target.md
- The ANTLR Mega Tutorial