こんにちは、株式会社LegalOn Technologies の検索・推薦チームでエンジニアをしている、佐藤です。
弊社では LegalForce という製品で、お客様がアップロードした契約書を条文単位で検索ができる、条文検索機能を提供しています。 条文検索では既に契約書本文の Query Auto Completion (クエリ自動補完, 以下 QAC)が提供されており (*1)、今回は契約書のタイトルやファイル名などで絞り込み検索を行う際に利用される QAC の開発を行いました。
本記事では今回開発した QAC を実現する上で課題となった QAC データの更新について、継続的な更新を行うために検討したシステム設計や運用方法を紹介したいと思います。
(*1) 別の記事で詳しく紹介されています。
目次
- 絞り込み検索のための QAC
- QAC データ更新における課題
- Completion 更新戦略
- イベント駆動型アーキテクチャによる非同期更新
- イベント設計
- 処理に失敗したイベントのハンドリング
- 差分更新によるデータ不整合の解消
- 今後の展開
- まとめ
- メンバー募集中!!
絞り込み検索のための QAC
今回開発した QAC は契約書のタイトルやファイル名など(以下 メタデータと呼ぶ)で契約書の絞り込み検索を行う際に利用されるものです。
ユーザーが契約書を検索する際に、検索フォームに入力途中のクエリ文字列から補完したクエリをサジェストすることで、効率的に絞り込みができるようになることを期待しています。
例えばユーザーが 「秘密」と入力した場合、「秘密」が含まれる契約書のメタデータの値が返ります。メタデータの要素は1つではなく複数返る可能性があり、下の例のようにタイトル・ファイル名など複数のメタデータが返ります。
ユーザーから「秘密」と入力された際に QAC が返すメタデータ例
{ "title": ["秘密情報", "秘密保持"], "filename": ["秘密情報管理規定.docx", "秘密保持契約書.docx"] }
また、自動補完キーワードの検索には、Elasticsearchを利用しており、インメモリで高速なキーワードのルックアップを可能にする Completion Suggester で実現しています。
下の図のように、QAC API が入力中のクエリ文字列を受け取り、Elasticsearch に対して検索を行い、返されるキーワードをメタデータとしてユーザーにサジェストします。
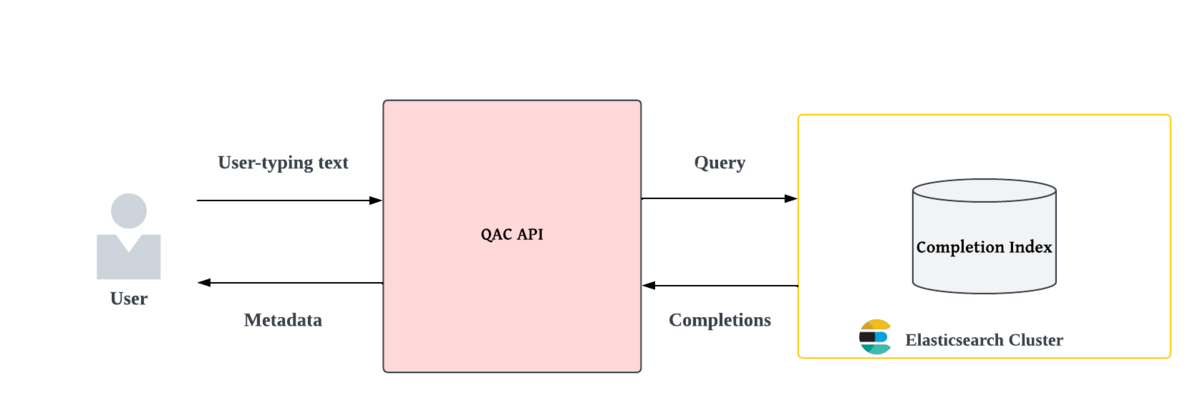
QAC データ更新における課題
契約書のメタデータはユーザーによって日々更新されるため、契約書メタデータの更新に追従して、自動補完キーワードも更新し同期をとる必要があります。
特に削除に関してはより厳密に同期していく必要があり、既に削除された契約書のメタデータが自動補完キーワードとして表示されてしまうと、サジェストされたキーワードからの検索結果が0件になる(以下 0件ヒット) ため、ユーザーの検索体験を損ねます。
自動補完キーワード(以下 Completion)と契約書(以下 Document)の関係を下図に示します。
これを見ると、Document A、Document B、Document C が同じ タイトル「秘密保持」を持っています。このように、複数の Document が同じメタデータの値を持つ可能性があります。
これは、Completion と Document が1対多の関係になっていると言えます。
そのため Completion を削除する際はその Completion を参照する Document が他に存在しないかを確認する必要があります。

上の例で言うと、Document A のタイトルが変更されたとしても、Completion X は他の Document に参照されているため、削除しません。
一方、Document D のタイトルが変更された場合、「損害賠償」をタイトルに持つ Document は存在しないため、Completion Y は削除します。
※ 補足ですが、契約書が更新されてから、自動補完キーワードが反映されるまで多少のタイムラグ(1分程度)は許容し、リアルタイムでの更新の反映は必須要件とはしませんでした。
Completion 更新戦略
Document 更新に伴い Completion を更新して同期をとる方法は大きく分けて以下の2つの方法があります。
全件入れ直し
定期的にバッチで全件 Document のメタデータを精査して、Completion を全て入れ直す
メリット
- 全件入れ直しになるため2の方法で問題となるデータ不整合が発生しない
デメリット
Document 数が増えると、バッチ実行時間が長くなりスケールしない
並列でバッチを実行することで、実行時間を短縮できますが、同期先の検索エンジンに負荷を与えすぎないように実行する必要があり並列数に限界があります
バッチが実行されるまでの間、同期が行われず差分が発生する
差分更新
Document メタデータが更新された際に、更新されたメタデータの Completion を更新する
メリット
- 差分更新になるため、一度に更新するデータは少なく済む
- Document の更新が Completion に反映されるまでのタイムラグが短い
デメリット
- 一度更新に失敗するとそれ以降差分が発生し続けるため、データ不整合が起こりやすい
現状では、Document の数が多く、更新頻度はそれ程多くないことから、今回は2の差分更新を選択しました。発生しうるデータ不整合の対策については後述します。
イベント駆動型アーキテクチャによる非同期更新
差分更新を実現するためにイベント駆動型アーキテクチャを採用しました。

Document が更新された際に、以下のステップでキューを経由して、連携する QAC サービスがCompletion を更新します。
- Search API (Producer)が Document 更新リクエストを受け取る
- Search API が Document Indexに保存される Document を更新
- Document の更新情報をイベントとしてキューに送信
- QAC Worker (Consumer)が定期的にイベントをキューから受信
- QAC Worker が受け取ったイベントを利用して、Completion Index に保存される Completion を更新
また Document は Elasticsearch の Document Index に保存し全文検索を実現しています。 自動補完のための Completion Index は、負荷分散や可用性の観点から Document Index とは別クラスタで管理しています。
最終的に、更新時と検索時を合わせると以下のようなフローになります。(上が更新時, 下が検索時)

この構成を採用することによるメリット・デメリットは以下の通りです。
メリット
Producer と Consumer が疎結合になり各コンポーネントの責務がシンプルになる
- Consumer で問題が発生した場合に、Producer に影響を与えることがない
- 将来的に QAC 以外の別の Consumer を追加することが可能で拡張性に優れている
キューがバッファの役割を果たし、処理しきれないイベントはキューに保存され、非同期で Consumer の処理速度に応じて処理することが可能
Completion インデックスのデータ構造上 (*2)、Completion の更新は負荷が高い処理になります。Document の更新頻度が突発的に高くなった場合、中間バッファとなるキューにイベントのデータを置くことで、Consumer である QAC Worker が過負荷になることを防ぎます。
処理に失敗したイベントを記録・リプレイすることが可能 (後述)
Consumer は必要に応じてスケールアウト可能
デメリット
イベント送受信に失敗した場合や Consumer でイベント処理に失敗した場合、データ不整合が発生する (対策については後述)
リアルタイムに同期ができない
非同期で更新するため、Document が更新されてから Completion が更新されるまでの間、一時的にデータが同期されていない期間が発生します。特にキューにイベントがたくさん溜まっている場合は、同期されるまでのタイムラグが長くなります。
今回はリアルタイム性は必須要件ではなかったため許容しています。
(*2) Completion Suggester で用いられるインデックスは、一般的に検索で使われる転置インデックスと異なり、高速に自動補完結果を返すために最適化されたグラフ構造になっており、更新の度に発生するグラフの再構築が重いためです。
イベント設計
以下は実際に QAC で利用した Document のメタデータ追加時のイベント例です。
{ "tenant_id": "tenant1", "fields": [ { "name": "title", "values": ["共同研究契約書"] }, { "name": "filename", "values": ["秘密保持契約書.docx"] } ], "event_type": "document attribute created", "doc_count_increment": 1, "failure_count": 1, "timestamp": "2022-06-13T07:34:54+00:00" }
主要な属性のみ説明します。
fields
Document メタデータの更新情報
Document メタデータは今後変更・追加されうるため柔軟性を保ちつつ、Consumer が統一的に処理できることを考慮し以下のようなスキーマになっています。
- 複数の Document メタデータが一括で更新されるケースを考慮し、
fieldsは配列に統一 - メタデータのフィールド名 (
name)とフィールド値 (values)は、任意に設定できるようにキー・バリュー形式で保持 - 1つのフィールドに対して複数のメタデータの値が設定される可能性を考慮し、
valuesは配列に統一
event_type
イベント種別
値には Document メタデータが作成・削除されたことを表す document attribute created, document attribute deleted が入ります。
doc_count_increment
Completionに紐づく Document 件数の増分
Completion に紐づく Document の数(以下 参照カウント)をこの値によって更新します。
メタデータが追加された場合は正の値、削除された場合は負の値が入ります。
またバルク更新により複数の Document が更新されることを考慮し、1と-1以外の値も代入可能な整数値にしています。
参照カウントは Completion の結果をランキングする際の重みとして活用し、参照される Document の件数が多いほど自動補完結果の上位にランク付けするといった使い方ができるため、各 Completion に参照カウントを保持するようにしています。
failure_count
イベント処理失敗回数
Consumer で一定回数以上処理に失敗した場合、このカウントがインクリメントされ、デッドレターキュー (*3) に保存されます。一定回数以上処理に失敗したイベントは破棄されます。
また Document メタデータが更新された際は、更新前のメタデータを Completion から削除して、更新後のメタデータを追加する必要があるため、メタデータの削除と作成のイベントを作成します。
(*3) 処理に失敗したイベント(メッセージ)を格納しておくキューのことをデッドレターキューと言います。失敗した原因を調査したり、後から失敗したイベントを再送信する際に利用します。
処理に失敗したイベントのハンドリング
主に下の図の4箇所で処理に失敗し、Document と Completion 間で正しく同期が行われずデータ不整合が起きる可能性があります。

不整合が発生しうるステップを順に見ていき、対策について説明します。
ステップ 2 で Document の更新に失敗した場合
イベントを送らないことで、不整合を回避できます。
ステップ 3 で Producer からキューへのメッセージ送信に失敗した場合
Document 更新に成功した後、イベント送信処理やキューを実現するシステムに問題がある場合に Completion は更新に失敗し不整合が起こります。
これを防ぐためには Document の更新とイベント送信をアトミックに実行する必要があります。
トランザクションがサポートされるデータベースでは2フェーズコミットや Transactional outbox パターン のような方法で同一トランザクションで実行することで整合性を担保できますが、分散型データストアである Elasticsearch の場 合トランザクションはサポートされていないため、今回はメッセージ送信に失敗した場合は、不整合を許容しエラーログを残し開発者に通知するに留めています。
ステップ 4 でキューからのイベントを受信する際に失敗した場合
イベント受信処理やキューを実現するシステムに問題がある場合に起こり得ます。
キューにイベントデータが永続化されている場合、後から復旧したタイミングで再度イベントを受信することで不整合を防げます。
ステップ 5 で Completion 更新に失敗した場合
想定しないデータ起因のエラーや、更新処理自体に問題がある場合、検索エンジンに対する過負荷による失敗など、様々な問題が発生する可能性が高いのはこのステップです。
イベントは Consumer が受信したタイミングでキューから削除されるため、受信後処理に失敗した場合は消えてしまいます。
対策として失敗したイベントは、デッドレターキューに保存し毎日夜間に一度自動でイベントのリプレイを行います。一定回数連続して失敗してデッドレターキューに溜まったイベントは削除しています。(*4)
(*4) デッドレターキューを作らず、メッセージブローカーが Consumer からメッセージが正しく受信されたことを示す確認応答(Acknowledgement)を受け取る仕組みを利用して、更新失敗時は、Ack メッセージを返却しないことでイベントをキュー内に保存し、時間を置いて自動リトライするといった方法もあります。
差分更新によるデータ不整合の解消
差分更新の特性上、一度差分の更新に失敗するとそれ以降データの不整合が発生し続けます。
一方で前項で説明したように、処理に失敗する箇所は複数あり、差分の更新に失敗しデータの不整合が発生する可能性をゼロにはできません。
データの不整合が発生した場合に特に問題となるのは0件ヒットです。削除されるべき Completion をユーザーにサジェストして検索された場合、Completion に紐づく Document が存在せず0件が返りユーザーの検索体験を損ねます。
このような不整合を解消するために、Document メタデータ削除イベントが送られたきた際は差分更新でを行いません。
まずデータソースである Document インデックスに問い合わせて Completion に紐づく実際の Document 件数を取得し、Completionが保持する参照カウントを更新し整合をとり、0件の場合は Completion を削除しています。

また途中で処理に失敗し、デッドレターキューに溜まったイベントをリプレイする際も他のイベントで更新対象の Completion が既に更新されている可能性があるため、同様の処理を行います。
今後の展開
Document の更新イベントをトリガーに、連携する周辺サービスも更新処理を行うというユースケースは他にも考えられます。
例えば以下のようなユースケースです。
- Document インデックス時に Document の特徴量を外部サービスで生成して検索時ランキングに利用したい
- Document のどのフィールドがどのような値で更新されたかをオペレーションログとして残しておきたい
今後このようなケースでも今回紹介した仕組みが活用できるのではないかと考えています。
まとめ
本記事ではイベント駆動型アーキテクチャを採用し QAC データを更新する方法について紹介しました。
各マイクロサービス間をイベントを利用して非同期にやり取りを行うことで各コンポーネントは疎結合になり、責務もシンプルになります。
一方でサービス間を連携する上でのプロトコルとなるイベントスキーマの設計や非同期処理に失敗した際のエラーハンドリングを適切に行うことが重要になります。
※ 本機能は、これから製品への搭載が予定されています。
メンバー募集中!!
株式会社 LegalOn Technologies では、検索システムの開発に興味のあるインターン生や、一緒に働くエンジニアを募集しています。気軽にご応募ください!