
はじめに
こんにちは。LegalOn Technologies 検索・推薦チームの臼井(jusui)です。
私たちのチームは、LegalOn Technologies が提供する主要サービス—「LegalOn Cloud」、「LegalForce」、「LegalForceキャビネ」—の検索・推薦システムの開発と運用を担当しています。 2024年7月に当チームから「Dataflow 実践開発セットアップ」を公開しました。
今回は、2024年4月から提供開始した弊社の新サービス「LegalOn Cloud」の初回リリースに向けて開発した Indexing pipeline とその後の改善についてご紹介します。具体的には、Cloud Pub/Sub と Cloud Dataflow を活用した Indexing pipeline の開発により、Elasticsearch への非同期文書登録を実現しました。本記事では、開発過程で直面したデータ整合性の確保と性能向上への取り組みに焦点を当てます。 本記事が検索システムを開発している方の参考になれば幸いです。
前提
本ブログで紹介する Dataflow Indexer 改善に関する前提条件は以下の通りです:
- インデックスリクエストは登録(Index)、部分更新(Update)、削除(Delete)をサポートしています。
- インデックスリクエストはメタデータとリクエストボディの全データを格納して送信します。
- インデックスリクエストは正しい順序で Indexing pipeline に到達すると仮定します。
- Pub/Sub はメッセージの順序指定を設定しています。(参考)
- 本ブログでは、データ不整合について言及します。データ整合性とは、検索インデックスに登録したドキュメントのフィールドと、インデックスリクエストの Single Source of Truth (SSOT) である RDB テーブルのフィールド間に生じる差異を指します。
Apache Beam と Cloud Dataflow の概要
Apache Beam(以下 Beam)
Cloud Dataflow(以下 Dataflow)
- Google Cloud が提供する大規模なストリームデータ処理とバッチデータ処理の統合サービス。Dataflow は Beam で定義されたパイプラインを実行するランナーの一つです。ランナーの役割は、特定のプラットフォーム上で Beam パイプラインを実行することです。 (参考)
- Beam で作成したパイプラインは、Dataflow の複数ワーカーにインストールされます。各ワーカーでは、データ変換などの処理がマルチスレッドで実行されます。
用語解説
パイプライン
Beam におけるパイプラインとは、データの集計、処理、変換、加工、および移動を行う一連の計算をカプセル化したものです。一方、当社の検索システムにおける Indexing pipeline は、Pub/Sub と Dataflow を用いてドキュメントを検索インデックスに登録するデータパイプラインを意味します。(参考)
テナント
当社が提供する「LegalOn Cloud」などのサービスは、マルチテナントモデルを採用しています。テナントとは、サービスを利用する顧客の契約単位を指します。マルチテナントについての詳細は、参考のブログで解説されています。(参考)
「LegalOn Cloud」1stリリースに向けた Indexing pipeline 開発
Dataflow を使った Indexer 開発
Beam で定義したパイプライン(緑)に Indexer を組み込み、Dataflow で起動することで、Pub/Sub からデータを非同期で取得する Indexing pipeline を構築しました。各 Dataflow ワーカー が Subscription からデータを取得し、加工後、Elasticsearch にインデックスリクエストを送信します。実際は、パイプラインで定義したデータ変換・加工を実行する PTransform によりインデックスリクエストを作成します。インデックスリクエストを実行する Index data も PTransform の1つとして定義しています。詳細は、Beam プログラミングガイドをご参照ください。
- PCollection: Beamにおけるデータの基本単位
- PTransform: PCollection に対する変換操作の定義

インデックスリクエストの流れ:
- 「LegalOn Cloud」上でユーザーが契約書をアップロード、もしくは既存の契約書を更新
- 「LegalOn Cloud」内部で契約書を解析後、「LegalOn Cloud」バックエンドから検索チームの Pub/Sub トピックにリクエストを送信
- Dataflow が Pub/Sub からリクエストを Subscribe
- Dataflow は受け取ったリクエストを加工し、インデックスリクエストを生成
- Dataflow から Elasticsearch にインデックスリクエストを送信
- Elasticsearch がドキュメントを Indexing
パイプライン実装や Dataflow ジョブの実行例は前回の検索・推薦チームテックブログ「Dataflow 実践開発セットアップ」をご参照ください。
QA でデータ不整合を発見
「LegalOn Cloud」ローンチに向けて Indexing pipeline の機能検証を行った結果、Elasticsearch インデックスの一部がリクエストとは異なる状態で登録されている事象を確認しました。調査を行ったところ、Pub/Sub で順序指定キーを設定しても、Dataflow 内部でインデックスリクエストの順序が入れ替わることがわかりました。たとえば、以下のようなドキュメントが検索インデックスにあった場合、フィールド content の更新を行うケースを考えます。
{ "_index": "test", "_id": "00000000-0000-0000-0001-000000000001", "_score": 1.00, "_routing": "00000000-0000-0000-0001-000000000001", "_source": { "doc_id": "0001", "title": "my contract", "content": "hoge" } }
リクエストA: "content” を “fuga” に更新
POST test/_update/1
{
"doc": {
"content": "fuga"
}
}
リクエストB: “content” を “piyo” に更新
POST test/_update/1
{
"doc": {
"content": "piyo"
}
}
更新リクエストAとBの順番が入れ替わると、最終的な検索インデックスには更新リクエストAが反映されてしまいます。しかし、ユーザーは "content" が "piyo" に更新されることを期待しています。この問題は更新だけでなく、登録や削除のリクエストにも影響します。順序が入れ替わると、検索時に本来ヒットするはずのドキュメントが存在しなかったり、登録や更新したはずの値が反映されていなかったりする問題が生じる可能性があります。
{ "_index": "test", "_id": "00000000-0000-0000-0001-000000000001", "_score": 1.00, "_routing": "00000000-0000-0000-0001-000000000001", "_source": { "doc_id": "0001", "title": "my contract", "content": "fuga" } }
反省点
「LegalOn Cloud」リリースに向けて、Pub/Sub と Dataflow を活用した非同期 Indexing pipeline を開発しました。当チームにとって Dataflow の採用は初めての挑戦でした。技術選定の理由として、Beam プログラミングモデルによるパイプライン構築の開発面での利点(参考)と、スケーラブルなフルマネージドサービスによる運用面でのメリットが挙げられます(参考)。
しかし、Dataflow の公式ドキュメントには順序に関する懸念も明記されていました。この経験から、技術選定時には公式ドキュメントを徹底的に精査することの重要性を痛感しました。
パイプラインの作成で指定したすべての変換がサービスで実行されますが、パイプラインを最も効率よく実行するために、それらは異なる順序で実行される https://cloud.google.com/dataflow/docs/pipeline-lifecycle?hl=ja
リリース後に振り返ると、Pub/Subで順序指定したデータが Dataflow 内で異なる順序で実行されると判明した時点で、他のツールの検討も含めて開発を進められたかもしれません。ただ、当時は「LegalOn Cloud」のリリースに向けたリソースが限られており、Dataflow を用いた解決策を模索しました。
リリースまでに解決しなければいけない課題
「LegalOn Cloud」のリリースまで時間が限られる中、データ不整合の問題を無視することはできません。最優先で取り組むべき課題は、Dataflow 内でリクエストの順序が入れ替わることによるデータ不整合の発生です。本ブログにおける「データ不整合」とは、検索インデックスに登録されたドキュメントのフィールドと、インデックスリクエストの Single Source of Truth (SSOT) である RDB テーブルのフィールド間に生じる差異を指します。この問題解決に全力を注ぎ、リリースに向けて邁進しました。
リリースに向けて奮闘
「LegalOn Cloud」リリースに向けて、Dataflow 内部でリクエストの順序が入れ替わっても、「データ不整合」の発生を防ぐことに取り組みました。しかし、発生を防ぐための明確な原因を特定できていない状態だったため、仮説検証を開始しました。
データの並列処理による順序入れ替えの可能性
我々は、Dataflowの並列処理による計算効率化がこの問題の原因ではないかと仮説を立てました。リクエストのサイズ、ワーカー、スレッドの負荷状況によって処理時間に差が生じ、それが順序の入れ替わりを引き起こす可能性が懸念されました。QA時に動作していたパイプラインは、Dataflow 上で複数のワーカーとスレッドでデータ変換を並列実行していました。そのため、一部のメッセージが時系列を追い越して処理されるケースが発生し、順序の入れ替わりを引き起こす可能性があると考えました。
例えば、Indexing pipeline が以下の順で更新リクエストを処理するケースを考えてみましょう。リクエスト側は、3つのリクエストを順番に実行し、最終的にドキュメント(doc_id: 123)を状態 C に更新することを想定しています。
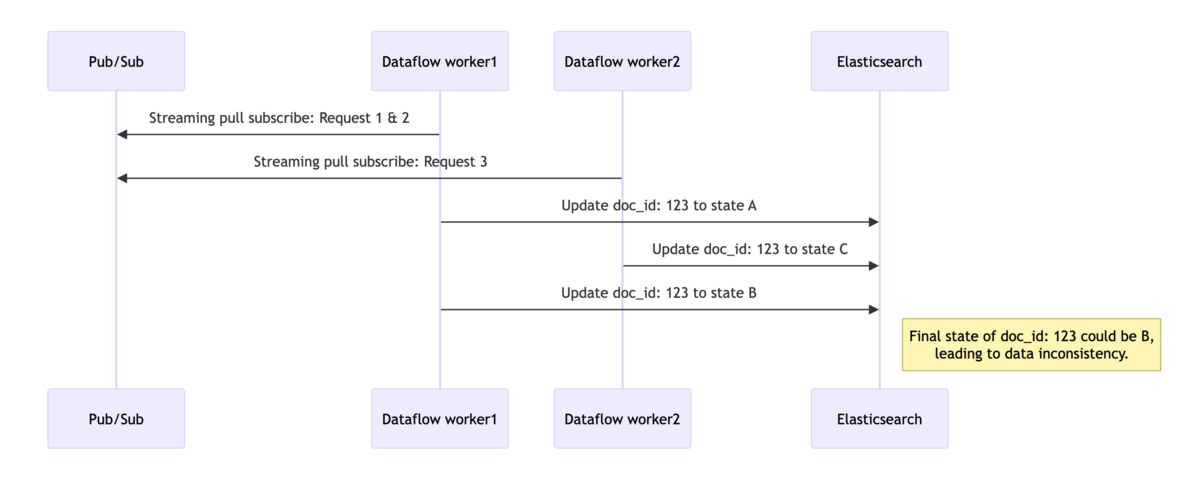
一方で、Dataflow は複数のワーカー(スレッド)が同時にメッセージを Subscribe し、データ変換を行い、Elasticsearch へインデックスリクエストを送信する可能性があると考えました。
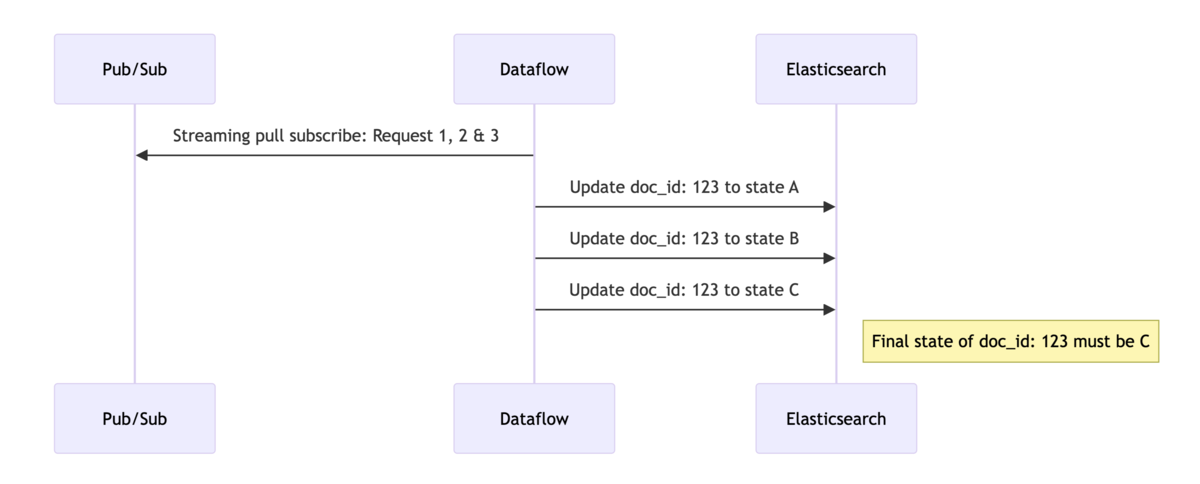
この並列処理により、ワーカー1がリクエスト1と2を処理している間に、ワーカー2がリクエスト3を先に処理してしまう可能性があります。その結果、リクエスト2が最後にドキュメントを更新し、最終的な検索インデックスの doc_id: 123 は状態Bとなります。これにより、RDB テーブルのフィールドと検索インデックスのフィールド間でデータ不整合が発生してしまいます。
リクエストのシリアル処理
この仮説に対する直感的な対策として、インデックスリクエストのシリアル処理による解決を試みました。処理時間の差を最小限に抑えるため、実行するワーカーとスレッド数を制限し、シングルワーカー、シングルスレッドでインデックスリクエストを処理する方法を採用しました。これにより、ワーカーやスレッドの負荷状況による処理時間のばらつきや、一部のワーカーのメッセージが時系列を追い越して処理されるケースを防ぐことを目指しました。
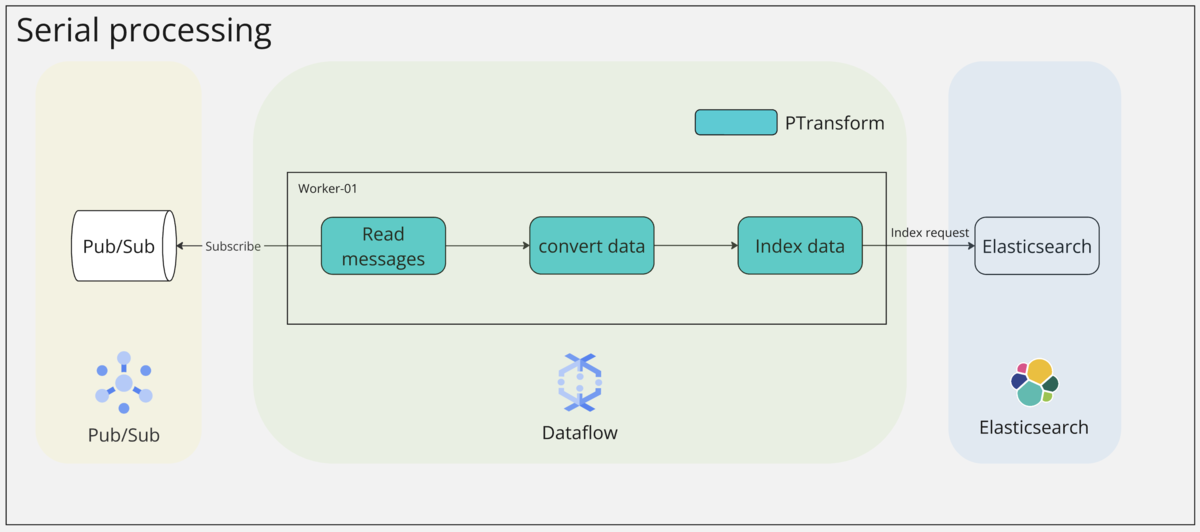
シリアル処理への移行は、Dataflow ジョブの実行オプションを変更することで検証できます。設定オプションに関する部分のみ記載しています*1。
experiments:SDK のプロセスを1つだけ使用する設定(参考)num_workers,max_num_workers:ワーカー数を1に設定(参考)number_of_worker_harness_threads:スレッド数を1に設定(参考)
# Makefile .PHONY: run-dataflow run-dataflow: poetry run python run_dataflow.py \ # Disable autoscaling --experiments "use_runner_v2,no_use_multiple_sdk_containers" \ # Set the number of workers to 1 and the number of threads to 1 --num_workers=1 \ --max_num_workers=1 \ --number_of_worker_harness_threads=1 \
シリアル処理の導入により、QA とE2Eテストを無事にクリアしました。また、この改善を組み込んだ Indexing pipeline を用いて、「LegalOn Cloud」の初回リリースを成功裏に達成することができました。
新たに浮上した課題
シリアル処理の採用によりデータ整合性は保たれたものの、Dataflow の処理能力が大幅に低下することが判明しました。
性能面の懸念
Dataflow をシングルワーカー、シングルスレッドで実行したことで、その性能が著しく低下しました。例えば、あるユーザーが大量のドキュメントをアップロードすると、それらは順次処理されます。その結果、大量アップロードの直後に別のユーザーがドキュメントをアップロードした場合、処理に大幅な遅延が生じる可能性があります。特に、この問題がテナントを横断して発生すると、ユーザー体験が悪化してしまうため、迅速な解決が求められました。「LegalOn Cloud」初回リリース時は、「LegalForce」などの既存サービスと比べて利用開始予定のテナント数が限られていたため、性能を犠牲にしてデータ整合性の確保を優先しました。
性能面の改善
シリアル処理の採用により、「LegalOn Cloud」の初回リリースは何とか成功しました。しかし、今後のサービス拡大を目指す弊社としては、初回リリースで明らかになった Dataflow indexer の性能制限の解消に早急に取り組む必要がありました。
リクエストの分割、集約とソート
Dataflow indexer の性能制限を解消するため、データ整合性を保ちつつ Dataflow の本来のスケーリング機能を活用できるパイプラインの構築に取り組みました。Beamの機能を駆使し、データの分割・集約・ソートを行うことで、結果整合性を確保しつつ性能を向上させたパイプラインへと改良しました。
パイプラインは、3つの要素で成り立っています。
- PCollection: パイプラインで処理するデータセット
- PTransform: パイプラインのデータ処理を行うステップ
- Subscribe したメッセージをインデックスリクエスト用に変換する処理、ソート処理等
- ワーカー内で複数のスレッドが PTransform の計算を並列で実行します。
- Aggregation PTransform: 事前に定義したキー等を用いてデータを集約する PTransform
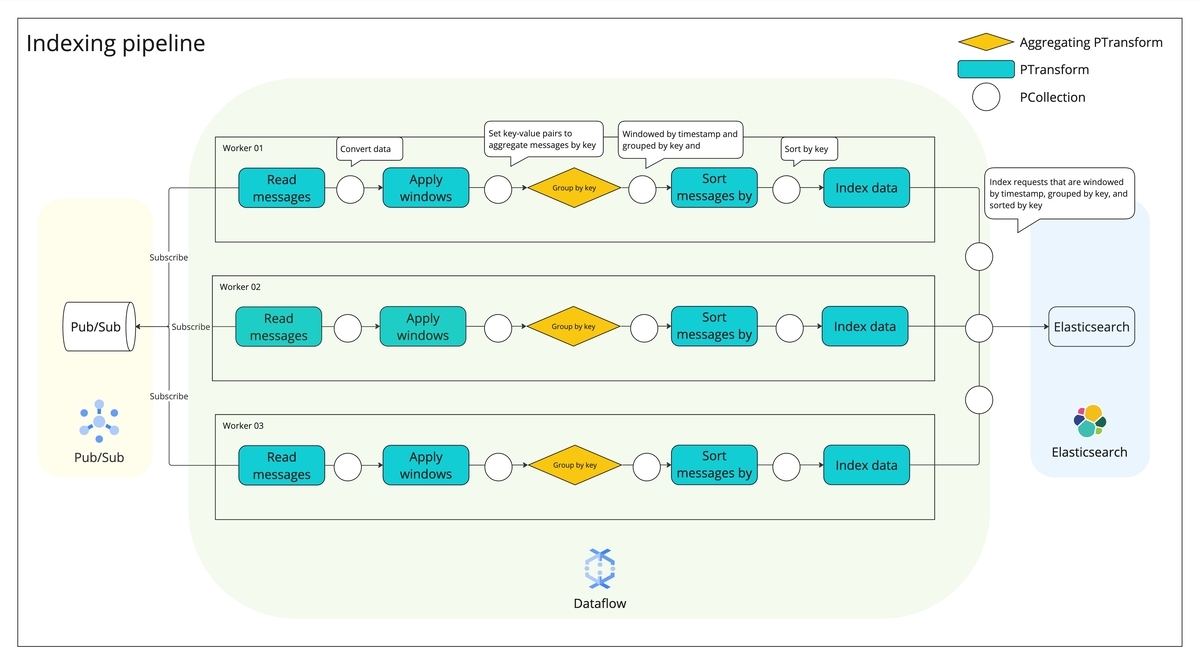
パイプライン構成は以下の通りです:
Pub/Sub I/O コネクタが Pub/Sub の各パーティションからメッセージを Pull Subscribe
メッセージの publish time を Element(インデックスリクエスト)に格納します。Publish time はリクエストのソートで利用します。なお、Pub/Sub では順序指定キーを設定していますが、これまでの調査で明らかになったように、Dataflow 内では順序指定が維持されません。
ウィンドウ処理を導入し、インデックスリクエストをタイムスタンプに応じて分割
実装と検証の容易さから、Fixed windowを採用しています。これは、重複のない一貫した時間間隔でデータを処理する方法です。(参考)
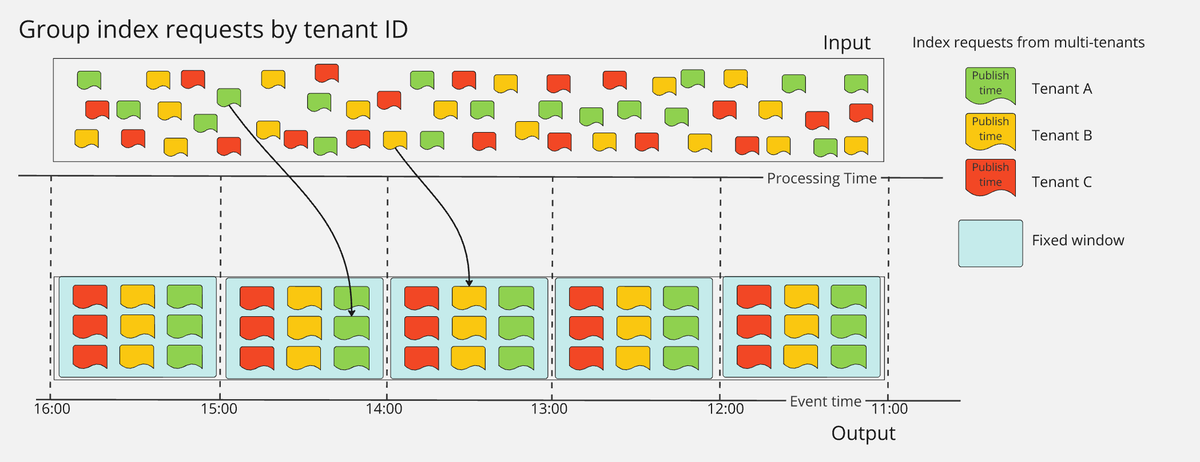 the-world-beyond-batch-streaming-101 Figure 10 を参考に図を作成*2。
例えば、図のようにインデックスリクエストをストリーミングしてパイプラインに入力する場合を考えます。各ワーカー内でパイプラインは、指定されたウィンドウ範囲内(例えば最初のウィンドウでは11:00~11:59)のタイムスタンプを持つすべてのデータを収集します。
the-world-beyond-batch-streaming-101 Figure 10 を参考に図を作成*2。
例えば、図のようにインデックスリクエストをストリーミングしてパイプラインに入力する場合を考えます。各ワーカー内でパイプラインは、指定されたウィンドウ範囲内(例えば最初のウィンドウでは11:00~11:59)のタイムスタンプを持つすべてのデータを収集します。分割したメッセージをキーで集約
適切な粒度でドキュメントを集約できるキーを選定します。例えば、テナントをキーにすることで、テナントごとにメッセージを集約できます。上図では、固定ウィンドウ内でテナントA、B、Cごとにメッセージを集約しています。この段階では、集約したリクエストが元のリクエスト順と一致していない可能性があります。
集約したメッセージをソート
結果整合性を保証するため、ソートキーの選定は慎重に行う必要があります。今回は、メッセージが Pub/Sub サーバに到着した時間(publish time)を使用しました。このステップで、Dataflow 内部で順序が入れ替わったメッセージを元のリクエスト順に修正します。
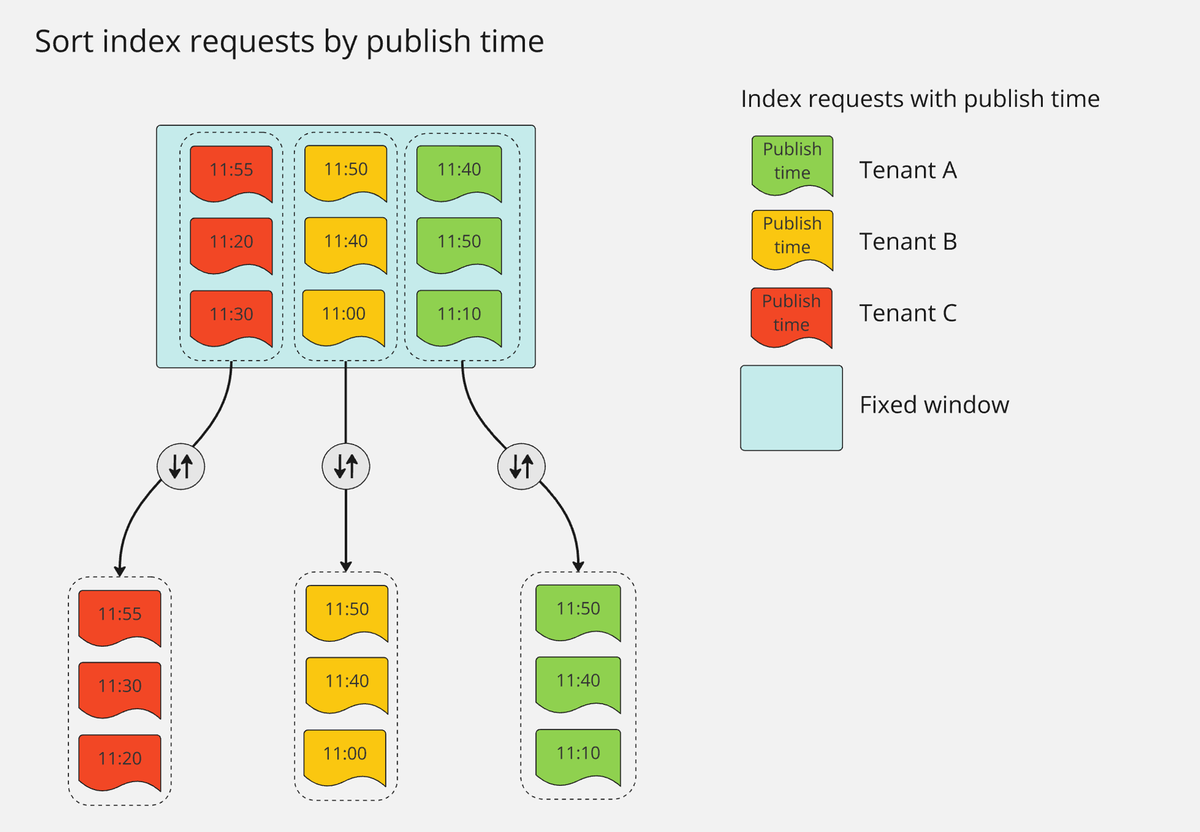 Step.2 の最初のウィンドウ(11:00~11:59)に注目すると、上のように図示できます。Step.3 で集約したメッセージを Publish time でソートすることにより、テナント A と C(緑と赤)のリクエスト順序が適切に修正されています。
Step.2 の最初のウィンドウ(11:00~11:59)に注目すると、上のように図示できます。Step.3 で集約したメッセージを Publish time でソートすることにより、テナント A と C(緑と赤)のリクエスト順序が適切に修正されています。ソートしたメッセージを用いて Elasticsearch にインデックスリクエストを送信
このように、インデックスリクエストをウィンドウで分割し、キー(例えばテナント)で集約し、信頼できるキーでソートすることで、リクエストの順序を維持することができます。これらの処理を実装したコードは以下のような構成です。前回のブログを参考に既存のパイプラインに分割、集約、ソート機能を追加しました。なお、前回のブログで既出の変換クラスは省略しています*3。
# pipeline.py import logging from dataclasses import dataclass from typing import Any, Generator, Iterable, List, Optional from apache_beam import DoFn, GroupByKey, Map, ParDo, Values, WindowInto, io from apache_beam.options.pipeline_options import PipelineOptions from apache_beam.pipeline import Pipeline from apache_beam.pvalue import PCollection from apache_beam.runners.runner import PipelineResult from apache_beam.transforms import window from apache_beam.transforms.core import PTransform from apache_beam.transforms.window import Duration from lib import get_repo @dataclass class Element: """ Represents an element of the Apache Beam pipeline. Attributes: request_body (Any): The request body being processed. """ request_body: Any publish_time: Optional[str] = None class PipelineRunner: def __init__( self, subscription: str, index: str, pipeline_args: list[str] = [], ): self.subscription = subscription self.index = index self.pipeline_args = pipeline_args self.pipeline = None self.pipeline_result: Optional[PipelineResult] = None def run(self) -> PipelineResult: """ Runs the pipeline and returns the result. Returns: PipelineResult: The result of running the pipeline. """ # Set `save_main_session` to True so DoFns can access globally imported modules. pipeline_options = PipelineOptions( self.pipeline_args, streaming=True, save_main_session=True ) logging.info("Start running pipeline") self.pipeline = Pipeline(options=pipeline_options) # Subscribe messages from Pub/Sub pubsub_result = ( self.pipeline | "Read data from Pub/Sub" >> io.ReadFromPubSub( subscription=self.subscription, with_attributes=True, ) ) # Window data by fixed window window_result = pubsub_result | "Window data" >> WindowInto( windowfn=window.FixedWindows(size=int(self.window_size)), allowed_lateness=Duration(seconds=int(self.allowed_lateness)), ) # Convert Pub/Sub message to index data to Elasticsearch convert_result = window_result | "Convert Pub/Sub to proto" >> ParDo( ConvertPubsubMessageToProto() ) # Group data by tenant ID group_values_from_key = ( convert_result | "Get values from messages grouped by tenant ID" >> GetValuesFromGroupedByTenantId() ) # Sort messages by publishing time sort_message_by_publish_time = ( group_values_from_key | "Sort messages by publish time" >> ParDo(SortElementsByPublishTime()) ) # Index data _ = ( sort_message_by_publish_time | "Index content" >> ParDo(Indexer(self.index)) ) self.pipeline_result = self.pipeline.run() return self.pipeline_result def get_tenant_id_element_pair(element: Element) -> tuple[str, Element]: """ Make a pair of tenant ID and element for grouping messages Args: element (Element): Element Returns: tuple[str, Element]: A pair of tenant ID and element """ request = element.request_body tenant_id = request.tenant_id return (tenant_id, element) class GetValuesFromGroupedByTenantId(PTransform): """ A PTransform class that extracts the values from a grouped message. This class takes a PCollection of key-value pairs, groups them by key, and returns a PCollection of the values. 1. Make a tenant ID and element pair for grouping message 2. Group messages by tenant ID 3. Get the value of each pair from element Args: None Returns: PCollection: A PCollection of the values from the grouped message. """ def expand(self, pcoll: PCollection): return ( pcoll | "Make key and element pair for grouping message" >> Map(lambda x: get_tenant_id_element_pair(x)) | "group messages by key" >> GroupByKey() | "Get the value of each key-value pair from element" >> Values() ) class SortElementsByPublishTime(DoFn): """ A DoFn class that sorts elements by their publish time. """ def process(self, elements: Iterable[Element]) -> Generator[List[Element], None, None]: """ Sorts the given elements by their publish time. Args: elements (Iterable[Element]): The elements to be sorted. Yields: Generator[List[Element], None, None]: A generator that yields the sorted elements. """ logging.info("Start to sort elements by publish time") yield sorted( elements, key=lambda x: x.publish_time, ) class Indexer(DoFn): """ A class that handles index requests for Elasticsearch. This class processes index requests and updates the Elasticsearch index. Considering the observability, it also sends the trace data to the Cloud Trace. Args: endpoint (str): The endpoint of the Elasticsearch server. index (str): The name of the Elasticsearch index. """ def __init__(self, endpoint, index): self.endpoint = endpoint self.index = index def setup(self): """For each batch, the setup method is invoked.""" self.repo = get_repo(self.index_name, self.endpoint) def process(self, elements: Iterable[Element]) -> Generator[Element, None, None]: """ Process the given elements and yield the processed elements. Args: element (Iterable[Element]): The elements to be processed. Yields: Generator[Element, None, None]: The processed elements. """ for element in elements: yield self.repo.index(element=element.request_body)
Makefile にまとめた Dataflow ジョブ起動コマンドでは、固定ウィンドウサイズ(window_size)と許容する最大遅延時間(allowed_lateness)を指定できるようにしています。弊社では、リクエスト構造や負荷試験結果に基づいてこれらのパラメータを決定しました。負荷試験の際は、オートスケーリングを無効化し、運用上想定される最大ワーカー数での性能を見積もりました。既出の起動オプションは省略しています。
# Makefile .PHONY: run-dataflow run-dataflow: poetry run python run_dataflow.py \ ... # specify window size and allowed lateness --window_size=$(WINDOW_SIZE) \ --allowed_lateness=$(ALLOWED_LATENESS) \ # Enable horizontal autoscaling --autoscaling_algorithm=THROUGHPUT_BASED --max_num_workers=$(MAX_WORKERS)
機能検証
データ不整合を検知する大規模テストを実施
実装ロジックを変更したため、データ不整合を検知する大規模テストを実施しました(Googleのソフトウェアエンジニアリングを参考*4)。ドキュメントを状態 A, B にそれぞれ変更するリクエストを Indexing pipeline に対して順番にリクエストし、最終状態が A になっている数を入れ替わりの発生数と判定します。
仮に Dataflow 内部で順番が入れ替わった場合、doc_id: 123 の最終状態は A になります。
⚠️ 機能検証を目的としているため、入れ替わりが発生しやすくなるよう、意図的に非常に短い間隔で更新リクエストを送信しました。実際の運用では、ユーザーがWeb UI上で操作することでインデックスリクエストが発生することが多いため、発生の頻度は低くなります。
このような基本設定で大規模テストを実施し、新機能実装前後での順序の入れ替わりを検証しました。複数のドキュメントを2つの異なる観点で更新するテストを行いました:
- 1テナント × 100ドキュメント:あるテナントで100ドキュメントを状態 A, B へ更新するリクエストを合計200回送信
- 100テナント × 1ドキュメント:1つのドキュメントを状態 A, B へ合計 2回更新するリクエストを100の異なるテナントで実施
Indexer の機能改善を確認
データ不整合が発生したドキュメント数を表にまとめました。比較のため、シリアル処理を行う Indexer でも同様のテストを実施しました。
| シリアル処理 Indexer | 改良版 Indexer | |
|---|---|---|
| 1 テナント × 100 ドキュメント | 43 | 0 |
| 100 テナント × 1 ドキュメント | 4 | 0 |
| 1 テナント × 1000 ドキュメント | (未測定) | 0 |
| 1000 テナント × 1 ドキュメント | (未測定) | 0 |
シリアル処理 Indexer のテスト結果は予想外の問題を浮き彫りにしました。1テナントで100ドキュメントを2回更新するテストでは、43件のドキュメントが意図した結果と一致しませんでした。さらに、100の異なるテナントで単一ドキュメントを2回更新するテストでは、4テナントでデータ不整合が発生しました。これまで大規模テストを実施していなかったため、E2EテストやQAでこれらの問題を見逃していました。この経験から、今後の開発・デリバリプロセスに大規模テストを組み込むことの重要性を痛感しました。
調査の結果、開発当初の Indexer と同様にリクエスト順の入れ替わりが問題の原因でした。Google Cloud の公式ドキュメントにも以下のような記載がありました。
Pub/Sub と Dataflow でデータパイプラインを構築する場合、Dataflow でのメッセージの順序指定は推奨されていません。 • Pub/Sub I/O コネクタでは、メッセージの順序指定が保持されないことがあります。 https://cloud.google.com/dataflow/docs/concepts/streaming-with-cloud-pubsub?hl=ja#message-ordering
一方、機能改善後の Indexer では、試行するドキュメント数を1000件まで増やしてもデータ不整合は発生しませんでした。これは、リクエストの集約とソートによってデータ不整合の発生確率を大幅に低減できたことを示しています。
性能改善
機能改善を経て、改良版の Dataflow indexer をリリースしました。これにより、データ整合性を高く維持できるようになり、同時に性能面での向上も確認できました。
スループットの性能改善
Dataflow を複数のワーカーとスレッドで起動し、パイプラインを並列処理できるようになったことで、Dataflow の真価が発揮されました。計算リソースを効率的にスケールすることでスループットが大幅に向上し、Pub/Sub で発生していたリクエストの滞留が劇的に減少しました。
以下のグラフは、2024年 7月3日から 7月9日までの1週間の Pub/Sub へのインデックスリクエストの分布を示しています。縦軸は単位時間あたりのリクエスト数を表します。グラフから、土日を除いて Indexing pipeline に一定の流量でリクエストが届いていることがわかります。
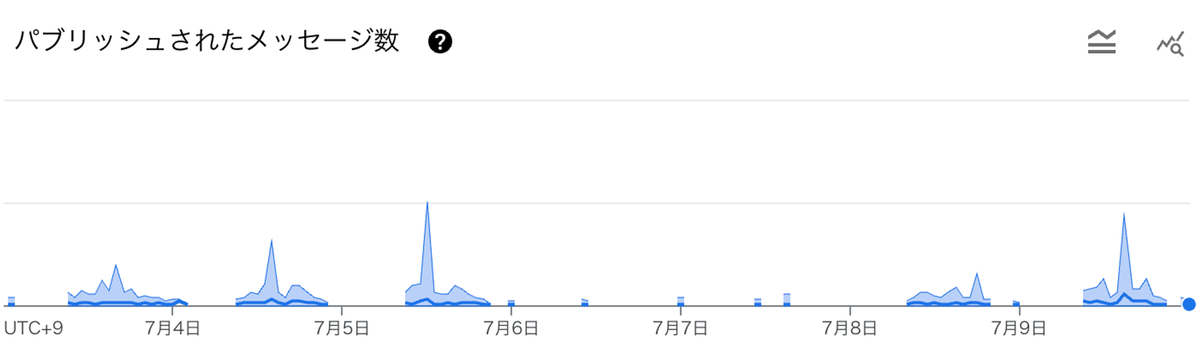
7月4日夜に改良版 Dataflow indexer を複数ワーカーでデプロイし、シリアル処理との比較検証を実施しました。同期間のリクエストに対して Subscription の最も古いメッセージの経過時間を確認したところ、顕著な改善が見られました。以下のグラフの縦軸は経過時間を表しています。
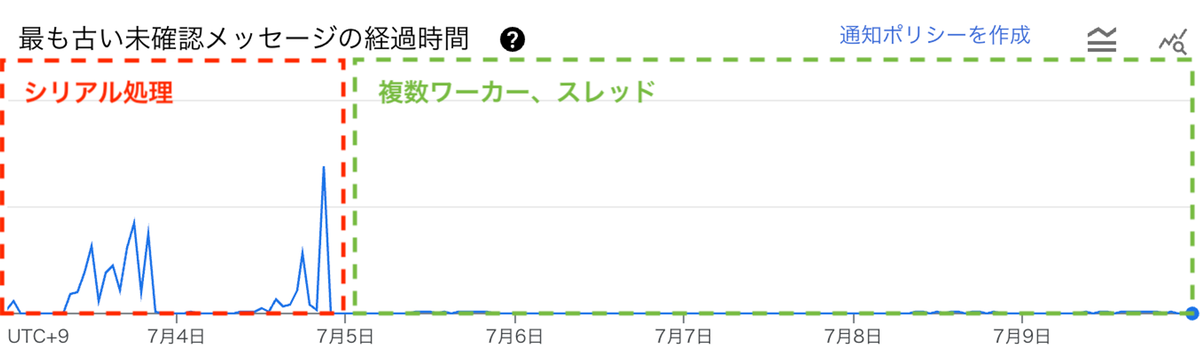
- 改善前(赤):シリアル処理により、大量のドキュメントアップロードがあった場合、後続のアップロードに長い処理待ち時間が発生します。
- 改善後(緑):メッセージの集約機能を導入したことで、集約キーごとに異なるスレッドでリクエストを処理できるようになりました。その結果、リクエスト間の処理待ちの影響が大幅に減少しました。
同様に、Subscription における未確認(Ack されていない)メッセージ数の変化を検証しました。7月5日に新機能を適用した後、未確認メッセージ数が劇的に減少しました。グラフの縦軸は未確認メッセージ数を示しています。
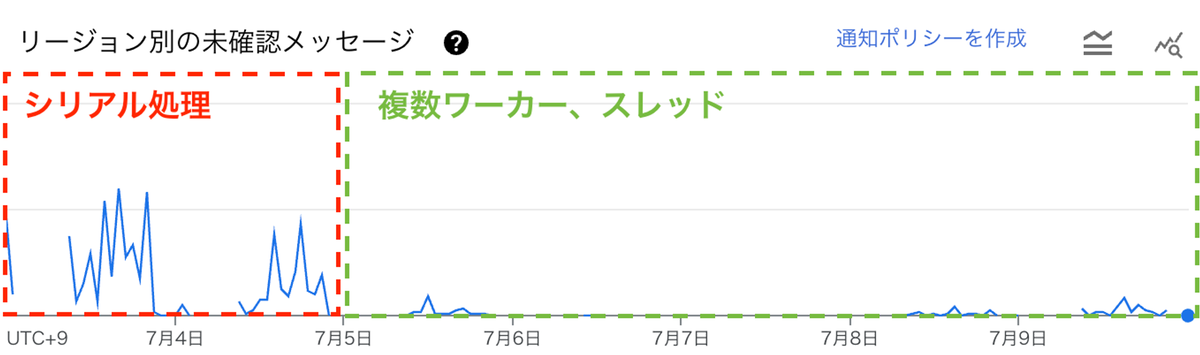
- 改善前(赤):シリアル処理によりスループットが低く、Pub/Sub にメッセージが滞留しています。短い時間でメッセージを処理できないことが課題でした。
- 改善後(緑):複数ワーカーとスレッドでリクエストを並列処理できるようになり、スループットが大幅に向上しました。その結果、メッセージが Pub/Sub に長時間滞留するケースが減少しました。
レイテンシの性能改善
スループットと同様に、データ整合性の問題を大幅に軽減したことで、Dataflow が計算リソースを効率的にスケールできるようになりました。その結果、Pub/Sub におけるレイテンシが劇的に改善しました。
レイテンシ性能の測定には Subscription を使用しました。具体的には、最も古い未確認メッセージの経過時間の最大値をCSVでダウンロードし、その値(秒単位)の平均を比較しました。改善前後でそれぞれ1週間分のデータを集計して比較を行いました。
集計結果では、メッセージの平均処理待ち時間が222.71秒から3.16秒まで大幅に改善されました。これは処理待ち時間の98.58%短縮を実現したことになります。
| レイテンシ[秒] | |
|---|---|
| 改善前 | 222.71 |
| 改善後 | 3.16 |
わかったこと
- Dataflow は、ワーカー数やスレッド数に関係なく、Beam で構築したパイプラインを効率的に実行します。そのため、PTransform などのデータ変換が必ずしもリクエスト順に処理されるとは限りません。
- メッセージのウィンドウ処理、集約、ソート機能を活用することで、パイプライン内で順序が入れ替わったメッセージを、リクエスト側の意図した順番に補正できることが判明しました。この方法により、インデックスパイプラインに起因するデータ不整合の発生頻度を大幅に低減させることに成功しました。
さらなる改善に向けたアイデア
- ウィンドウ処理の最適化:Fixed windowでは、固定時間でデータを分割するため、大幅に遅延したメッセージが別のウィンドウで処理されます。このとき、シリアル処理で懸念されたリクエスト処理の順序逆転が発生する可能性があります。対策として、Session windowなどの可変幅ウィンドウを採用し、指定時間以上データが途切れない限り一つのウィンドウとして扱うことで、一連のリクエストをまとめて処理できます。
Elasticsearchの楽観的ロック機構の導入:これはデータ整合性をさらに向上させるための方策です。楽観的ロックの導入は、より一貫性のあるIndexing pipelineを実現できる可能性がありますが、実装には課題があります。この方法では、シーケンス番号とプライマリターム(
seq_no、_primary_term)を使用してドキュメントの変更を識別し、最新の状態でのみ更新を許可します。しかし、この実装には製品開発チームとの緊密な連携が必要です。また、複数のマイクロサービスからのリクエストを扱うIndexing pipelineでは、シーケンス番号とプライマリタームの同期が複雑になります。現在、この同期方法が確立されていないため、導入が容易ではありませんでした。(Optimistic concurrency control | Elasticsearch Guide [8.15] | Elastic)インデックスリクエストの同期方法の見直し:現行のインデックスリクエストは、リクエストにメタデータとリクエストボディの全データを含めて送信しています。代替案として、Fetch型アーキテクチャの採用が考えられます。この方式では、Indexing pipelineへのリクエストをメタデータのみに限定し、IndexerがドキュメントIDなどを基に、RDBなどから最新データを取得します。
まとめ
このブログでは、LegalOn Technologies の検索・推薦チームが Pub/Sub と Dataflow を用いて開発した非同期 Indexing pipeline について紹介しました。主な内容は以下の通りです:
- データ整合性の問題とその改善策(リクエストの集約とソート)の実装
- 大規模テストによるデータ不整合の低減を確認
- 性能改善の結果:スループットの向上、Pub/Sub でのリクエスト滞留の減少、処理待ち時間の98.58%短縮
- 今後の改善案:ウィンドウ処理の最適化、Elasticsearch の楽観的ロック機構の導入、インデックスリクエスト方式の見直し
これらの経験が、読者の皆様にとって有益な情報となれば幸いです。
謝辞
本プロジェクトの成功には多くの方々のご協力が不可欠でした。心より感謝申し上げます。不整合検知の大規模テストを実装してくださった smiyazato さん、負荷試験スクリプトを開発してくださった banbiossa さん、本ブログのレビューをしてくださった KosukeArase さん、WinField95 さん、コードのレビューをしてくださった maomao905 さん、検索・推薦チームを導いてくださったリーダーの takuyaa さん、そして、「LegalOn Cloud」製品開発チームの皆様、ありがとうございました。
終わりに
私たちのチームでは、一緒に働く仲間を募集しています。 ご興味がございましたら、以下のサイトからご応募いただくか、カジュアル面談をお申し込みください。お待ちしております!
参考資料
メッセージの順序指定 | Pub/Sub Documentation | Google Cloud
Apache Beam のプログラミング モデル | Cloud Dataflow | Google Cloud
マルチテナンシーとは?| マルチテナントアーキテクチャ | Cloudflare
パイプラインのライフサイクル | Cloud Dataflow | Google Cloud
Dataflow のメモリ不足エラーのトラブルシューティング | Google Cloud
Pipeline options | Cloud Dataflow | Google Cloud
Streaming 101: The world beyond batch – O’Reilly
PubsubMessage | Pub/Sub Documentation | Google Cloud
Pub/Sub から Dataflow に読み取る | Google Cloud
Optimistic concurrency control | Elasticsearch Guide [8.15] | Elastic