はじめに
株式会社LegalOn Technologies でデータエンジニアリングをしている 田中 晶 です。
LegalOn Technologies では、データドリブンな意思決定をするために、データ分析基盤や BI ツールの整備を行い、プロダクトに関わる多くの社員がデータを活用できる状態を維持し、さらなる活用を目指しています。
過去の啓蒙活動や整備の甲斐もあり、現在弊社で利用しているBIツールである Looker のライセンスは多くの社員に付与されており、またその活用も専門職だけでなく、営業部門の活用率も高いという利用率の計測結果も出ているほどです。
このように活用されているデータ分析基盤ですが、より高いデータの利活用水準を目指すためには、利用者や用途に関して、長期的に柔軟な利用状況の分析を行う必要がでてきました。
そこで幅広く Looker の活用度を測定するために使用状況やパフォーマンスに関する情報である System Activity をより有効活用するような仕組みを構築しました。
Looker の System Activity は活用しようとすると、その特性上データの取り込みとシステムが課題になります。
さらに、データ取り込みのシステムを既存のワークフローエンジンで実装する場合、クラスタ管理など費用や保守運用コストが必要になってしまいます。
そのような課題について BigQuery へのロードを Looker Action と Eventarc と Cloud Workflows を利用して、非常に低コストなサーバレスイベント駆動パイプラインとして実現した事例をご紹介いたします。
この仕組みを応用すれば、クラスタ管理が必要なワークフローエンジンがなく、専任のデータエンジニアがいないような組織でも、パイプラインを構築することが可能になります。
前提となるシステムの解説
詳細な解説に入る前に、みなさまに馴染みのないシステムもあるかもしれません。そこで事前に登場する個別のシステムについて簡単に解説いたします。
もしすでにご存じでしたら、この章は飛ばして読み進めることをお勧めいたします。
Looker
Looker は、LookML という独自言語を使用してデータモデルを定義し、データの整合性と再利用性を保つことができるビジネスインテリジェンスとデータ分析のためのツールです。
ダッシュボードやレポートの作成、共有が容易で、多様なグラフやチャートを用いたデータの可視化ができます。
System Activity
Looker の System Activity は、Looker インスタンスの使用状況やパフォーマンスに関する情報を提供するダッシュボードとレポートです。
どのダッシュボードやレポートが最も頻繁にアクセスされているか、どれが使用されていないかというコンテンツの利用状況を確認できます。
Looker Action
Looker Action は、Looker のデータやダッシュボードを外部のサービスやアプリケーション、例えば Slack・Google Sheets・Salesforce などと統合する機能です。
Looker からのデータを簡単にエクスポートして、他のツールやプラットフォームで利用することで、定期的なデータのエクスポートや通知を自動化できます。
Eventarc
Eventarc は、2020年10月に Preview となり、2021年4月に GA となった Google Cloud のサービスです。Eventarc は、Google Cloud の他のサービスと連携するイベント駆動型のアーキテクチャを構築できるようにするサービスです。これにより、Google Cloud の特定のイベントが発生したときに自動的にアクションをトリガーできます。
Cloud Workflows
Cloud Workflows は、2020年8月に Preview となり、2021年1月に GA となった Google Cloud のサービスです。Cloud Workflows を使用すると、インフラ管理やスケーリングを気にすることなく、Google Cloud の他のサービスと連携するワークフローを YAML で作成できます。
課題
ここでは課題について記載します。
一つ目の課題は Looker の System Activity の保存期間が決まっていることと、ユーザーが欲しい情報を取得できるような柔軟性がないことです。
- System Activity の保存期間
- System Activity の柔軟性
- Looker の仕様上、System Activity を定義している LookML はユーザーから編集することはできません
一つ目の仕様のため、90日間(または1年間)以上の Looker のアクセス履歴、クエリ実行履歴、利用率などを長期間にわたって分析することが困難でした。
また二つ目の仕様のため、Looker ユーザに関する分析を実施しようと思っても、柔軟な分析を行うことが難しい状況でした。
二つ目の課題は Looker の System Activity をそのまま取得するだけでは、後述する要求を満たす拡張性が得られないという課題です。
Looker の System Activity に関する分析は、データ分析基盤チームのアウトカムに繋がる重要な指標です。社内の Looker の利用拡大に伴って、幅広い期間や様々な切り口で効果検証を実施したい、と考えており、変わりゆく状況に合わせて自由に項目を追加・変更できる拡張性を確保する必要がありました。
しかし System Activity の項目は非常に多岐にわたり、事前に定義されているダッシュボードには現時点で 46 個ものタイルが含まれています。(タイルとは、集計を可視化した要素で、ダッシュボードはタイルで構成されます)
またこのタイルは、さらに細かいディメンションという指標の掛け合わせで構成されており、その数は現時点で約 145 個になります。(ディメンションは、データの特定の属性やカテゴリを示すフィールドです)
System Activity を分析しようと思うと、このように多様な切り口があるので、事前にすべての指標を定義し、取得しておくことが難しいです。なので、必要なときに必要なだけの指標を取得する拡張性のあるシステムが求められました。
- 任意に後から取得する指標を追加できる
- 出力する周期自体も、取得する指標ごとに任意で設定できる
このような要求のため、システムには柔軟に変更や設定ができるアーキテクチャが求められていましたが、いままでのデータ分析基盤の仕組みではこのような課題を解決することが困難でした。
システム構成
先ほどの課題に対して、作成したシステムアーキテクチャが以下図になります。
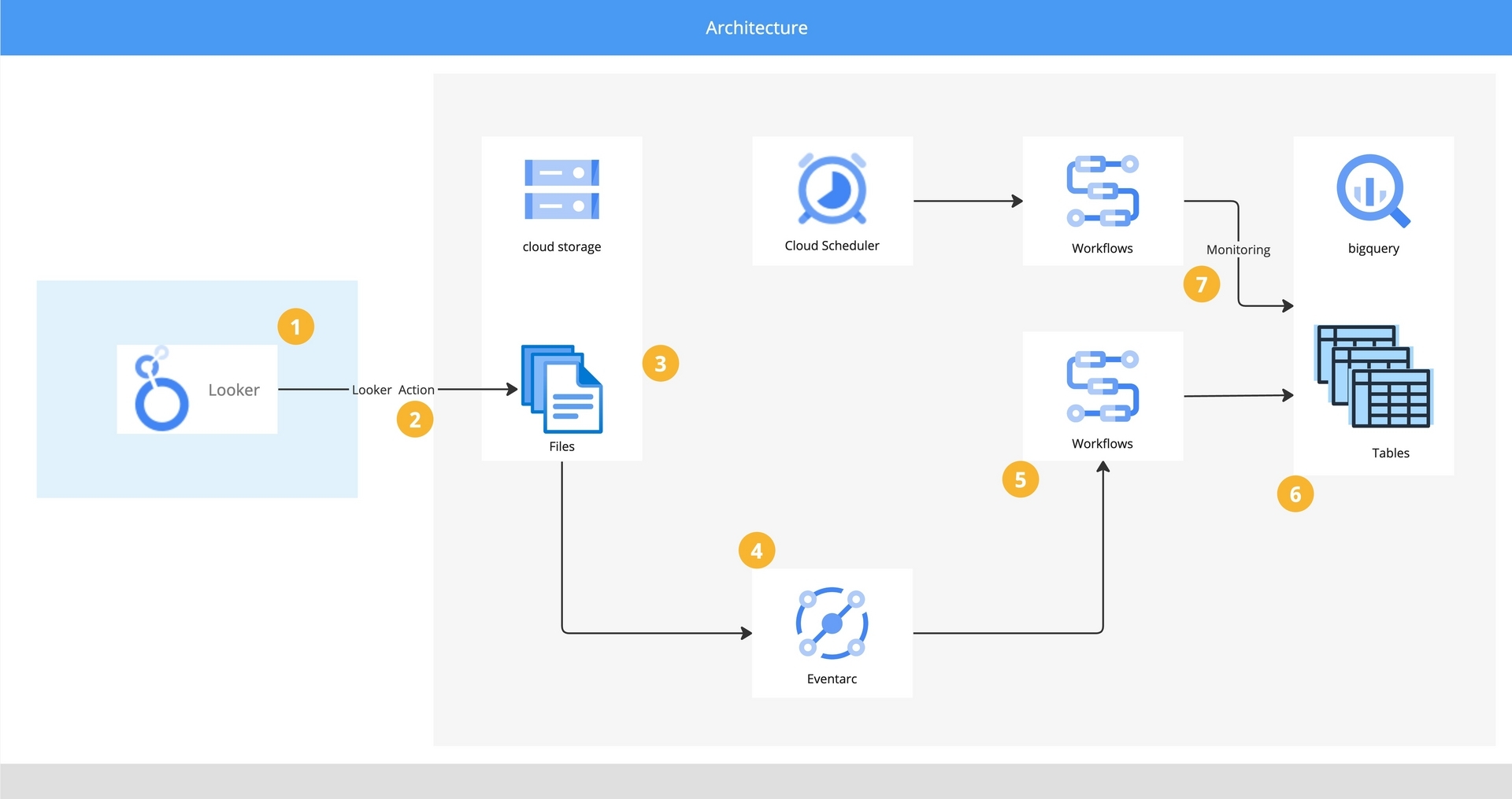
この章ではアーキテクチャ図の数字を元に、それぞれの詳細な役割について解説していきます。
わかりやすいように、データがどのようにシステムを経由して処理されるのか、という順番で各システムのポイントとなる設定について解説していきます。
1. Looker
まずデータの出力元となる Looker です。System Activity のダッシュボードから出力したい指標を Look というデータのクエリ結果を可視化する方法で保存しています。Look からスケジュールを設定して、Looker Action の設定をしています。
2. Looker Action
次にデータの出力スケジュールに関する設定をする Looker Action です。前提として、管理機能で 該当の Cloud Storage への書き込み権限を付与した権限設定をしています。
任意に後から取得する指標を追加できるようにするため、今回のケースでは Cloud Storage のパスに取り込ませたい BigQuery のデータセットやテーブル名、環境名を含めることで、複数の Looker Action を一つの Cloud Workflows で動的に BigQuery へ取り込めるようにしました。
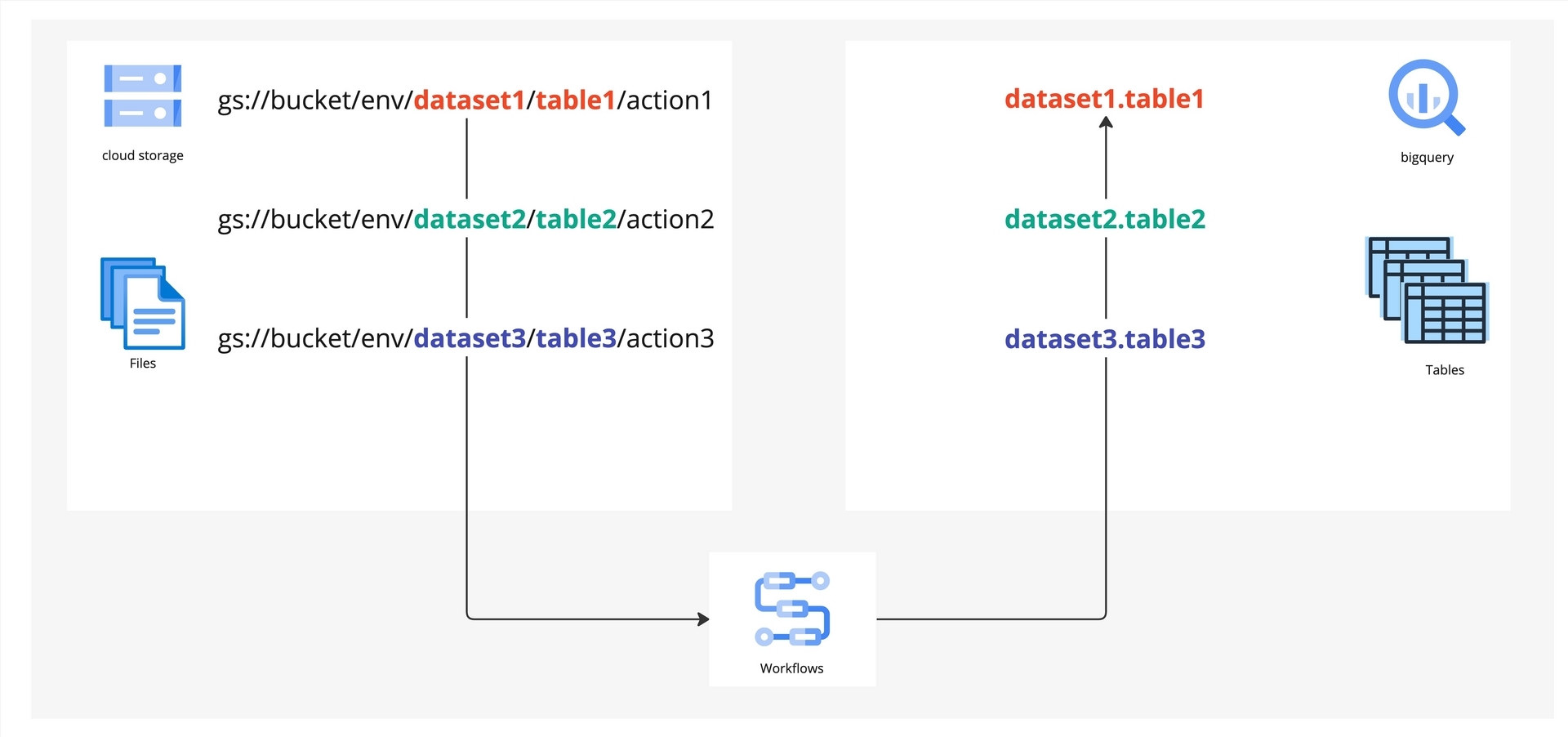
上の図「Cloud Storage から BigQuery へのマッピング」に具体的な例を示します。この図は、Cloud Storage のパスから BigQuery への動的なマッピングを示しています。例えば dataset1.table1 という BigQuery のテーブルに取り込みたいデータは gs://bucket/env/dataset1/tabel1/action1 というCloud Storage のパスへ保存します。このようにパスとテーブル名に対応をもたせることで、新たにデータを保存する必要が生じた際の設定変更を最小限に抑えることができ、データの取得と保存に対して柔軟な拡張が可能となりました。
またその他の Looker Action の出力設定は以下の通りとなります。画像のような設定画面で Looker Action を設定しています。
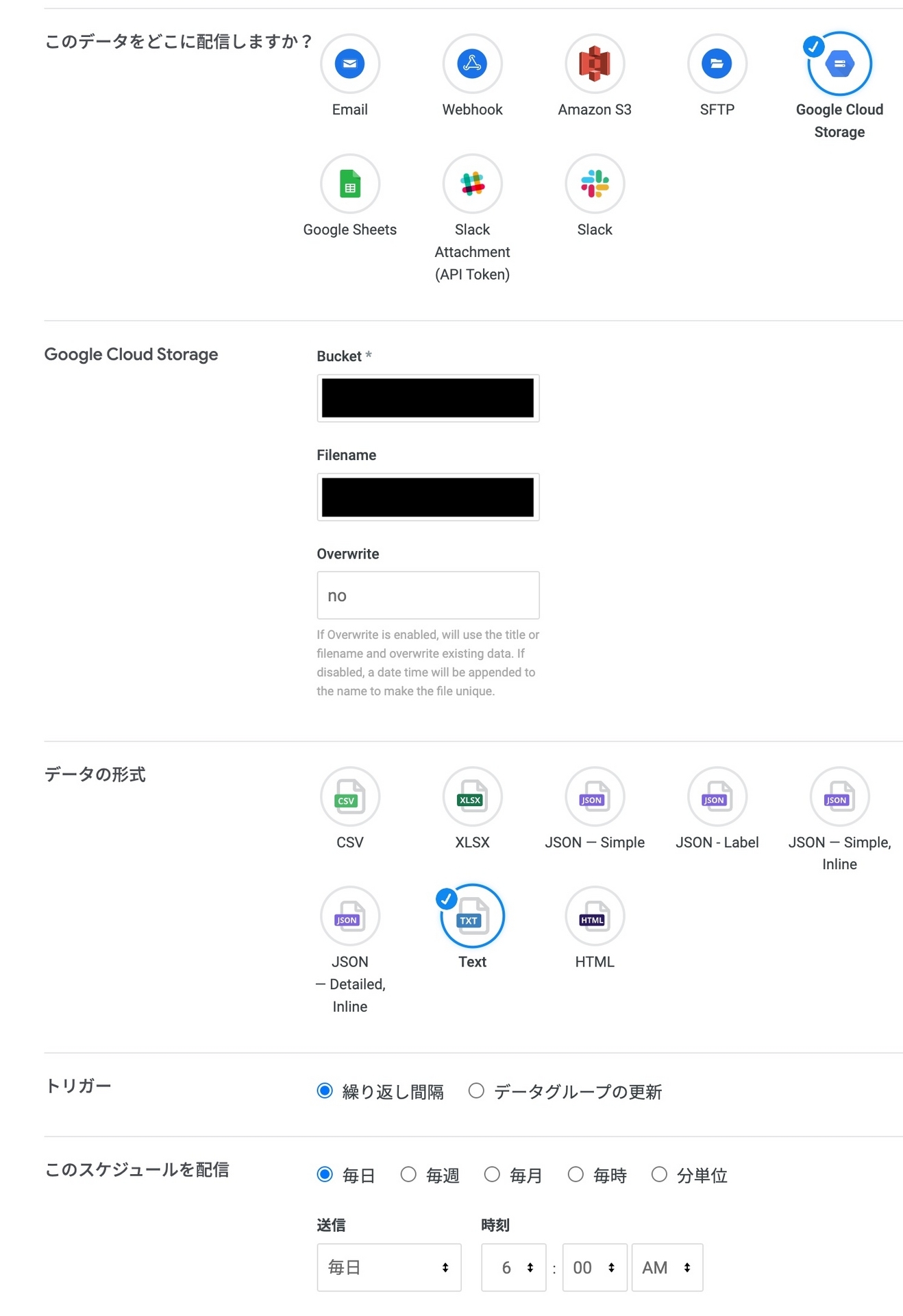
Overwrite の設定を「no」にすることで、suffix に13桁のマイクロ秒単位の unix timestamp が付与されて、実行ごとに異なるファイルが生成されます。この timestamp を後続の BigQuery テーブルのパーティショニングに利用しています。
データの書式は「Text」にすることで tab 区切りの tsv 形式が出力されます。tsv を選択することで、SQL クエリのような複雑な文字列が出力結果に含まれていても、制御文字で区切られるので、パースやインポート時にエラーが発生しなくなります。
3. Cloud Storage
出力設定の次は、データを保存する Cloud Storage です。前述の通り、Cloud Storage のパスを工夫することでシステムで動的に利用し、また意味のある単位のまとまりで管理できるようにしました。
4. Eventarc
データが保存されたら、保存したことを検知する Eventarc です。特定の Cloud Storage パス配下の storage.objects.create イベントで発火するように設定しました。
5. Cloud Workflows
保存イベントが発火した後には、 Cloud Storage から BigQuery にデータをロードする Cloud Workflows です。今回の Cloud Workflows の実装では、パーティションデコレータを利用するため、前述の suffix の timestamp から、パーティションに利用する文字列を作成しています。
パーティションデコレータを使用した上で WRITE_TRUNCATE で実行し、冪等性を担保しています。
6. BigQuery
そして最後に Cloud Workflows で処理されて、BigQuery のデータレイク層にデータがロードされます。スキーマは Terraform で管理しています。
7. モニタリング
今回はメインの処理に加えて、別の Cloud Workflows を作成しました。この Cloud Workflows の役割はモニタリングです。Cloud Scheduler から起動して特定のデータセット配下のテーブルをまとめて取得し、データが正しく存在しているかを確認しています。
システムの実行ステータスの成否に関わらず、期待したデータがあるかを判定してアラートを設定することで、確実に処理が実行されていることを担保しています。
システムのポイントと得られた恩恵
このシステムのポイントは、「イベント駆動アーキテクチャであること」、「動的にテーブルへデータをロードでき、拡張性があること」、「すべての構成要素がサーバレスであること」です。
これらのポイントを抑えたことで課題に対して、大きなメリットを得ることができました。
一つ目は、イベント駆動なアーキテクチャであることで、出力タイミングが変更された場合への柔軟性を獲得することができました。
Looker Action で、Looker 上から任意のタイミングで任意の情報を選択して設定することで、柔軟な運用を行うことが可能になりました。
また出力されたファイルを Eventarc でトリガーすることで、追加の開発をほぼ実施せずに変更や追加ができるようになりました。
従来のシステムであると、複数の異なるタイミングで取り込む必要が生じた場合、タイミングに合わせて新しいパイプラインが必要になりましたが、今回はファイルがアップロードされたことを起点として動作するので、取り込みタイミングに依存しない柔軟なシステムを構築することが可能となりました。
二つ目は、Looker Actionのところで説明を行いましたが、動的にデータをテーブルへロードすることで、新たな指標を追加しやすい拡張性を獲得することができました。
Cloud Storage のパスに対象となる取り込み先の情報を含め、それを Cloud Workflows で参照しています。Looker Action の設定を追加し、取り込み先の BigQuery テーブルを指定することで、対象が増えたとしてもシステム的な変更がほとんど必要ない、拡張性ある運用が可能になりました。
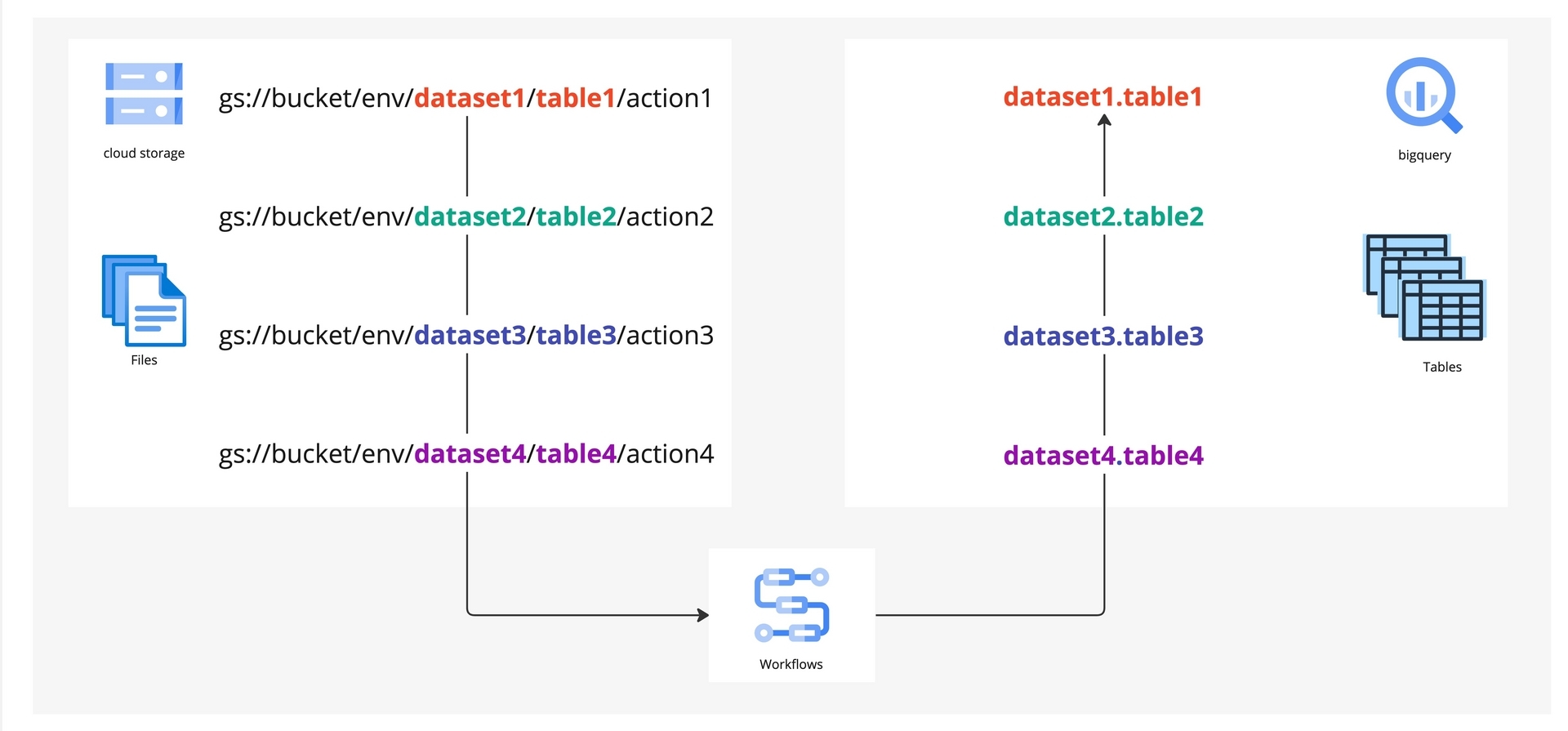
例えば、図のように System Activity の dataset1, dataset2, dataset3 をそれぞれ BigQuery のtable1, table2, table3 に取り込んでいて、ユーザ分析のために dataset4 が必要になったとします。ここで新たに行うことは、Looker Action に dataset4 の取得を追加し、Cloud Storage のパスにtable4 を指定するだけです。
先述したとおり非常に数の多い指標の中から、新たな指標が必要になった場合でも、大きなコードの追加や新しいパイプラインを新たに作らなくてはならない、といった追加開発をせずに必要な指標を増やすことができるようになりました。
BigQuery テーブルのスキーマ定義の更新は IaC(Terraform) が必要ですが、その準備さえ実施すれば、追加の System Activity の情報が必要になった場合でも、容易に取り込むことが可能です。
つまり GUI で可能な設定と少しの定義の変更で、新しい指標を新しいテーブルにロードすることが可能になったのです。
三つ目は、すべての構成要素がサーバレスで構築できたことで、Google Cloud の費用と人的運用コストをほとんど掛けずに保守運用することが可能になりました。
サーバレスアーキテクチャなので、基本的にはワークフローエンジン等のバージョンの影響を受けません。そのため継続的にシステムのバージョンアップ対応しなければならない、といったクラスタ管理等の人的運用コストをなくすことができました。
また主要な構成要素である Looker Action・Eventarc・Cloud Workflows はほとんど費用が発生しないので、 費用的な負担も非常に低くすることができました。[3, 4]
Eventarc について
今回 Eventarc を採用しましたが、Cloud Storage アップロードイベントを起点にしたアーキテクチャですと、「Cloud Storage の Pub/Sub 通知」という手法も昔から広く採用されてきました。[5]
従来からの手法ではなく、なぜ Eventarc を採用したか、という部分についてメリットも交えて解説します。
一つ目は、イベント管理の一元化という点です。従来からの手法では、イベント管理を統一的に管理することは困難で、イベントの管理が散逸してしまうという課題がありました。Eventarc を採用することで、複数のイベントがあった場合でも、統一的にハンドリングでき、管理の複雑さを軽減させることができました。
二つ目は、送信先の変更が柔軟であるという点です。従来からの手法では、特定のサービスにしか送信することができませんでした。この点でも Eventarc を使用するとイベントの送信先を柔軟に変更することができ、例えば Cloud Run、Cloud Functions、Cloud Pub/Sub、Cloud Workflows などにイベントをルーティングすることが可能になりました。
三つ目は、イベントの属性に基づくフィルタリングが可能なことです。従来からの手法では、ほとんど条件でフィルタリングすることができなかったので、受け取ったシステム側でフィルタリング条件を実装する必要がありました。この点についても Eventarc は、イベントの属性に基づいてイベントをフィルタリングする機能を提供しています。これにより特定の条件を満たすイベントのみを、ターゲットとするサービスにルーティングすることができるようになりました。
これらのことは、従来からの手法では実現することが難しい課題でしたが、Eventarc を採用することで以上のようなメリットの恩恵を得られるため、今回 Eventarc でのイベント駆動アーキテクチャを選択しました。
おわりに
今回のシステムを構築することで、過去長期間の利用率を測定することが可能になり、利用率の遷移から今後のチームとしての目標についても活発に議論できるようになりました。例えば直近ではお盆休みによる影響など顕著にあり、このようなデータが残ることから、季節性の変動について昨年度との比較をすることで、来年度以降より興味深い洞察が得られるかもしれません。
最後に、なぜ事例として公開したか補足します。
まず Eventarc や Cloud Workflows といった技術は比較的最近リリースされたサービスで、まだまだ事例として多くはないです。
また Looker の System Activity は社内のデータ活用を分析する際の重要な指標になります。しかし長期間の保存であったり、独自の分析を行う場合に課題が存在しています。
加えてシステムに連携する場合、追加の開発を検討する必要があり、すでに公開されている事例の中で今回のようなアーキテクチャの事例が少なかったために公開しました [6]
今回のアーキテクチャを採用すれば、Looker の System Activity をより活用できますし、それ以外のデータ取り込みに専任のデータエンジニア以外が応用することも可能です。
このブログを読んでくださったデータエンジニア、Looker に関わるエンジニア、パイプラインを構築するエンジニア、データの利活用を推進されるみなさまの助けになれば幸いです。
エンジニア募集中!
LegalOn Technologies では、データを活用しデータドリブンで意思決定を行える組織にするためのエンジニアを求めています。 もし興味があれば下記の募集要項をご覧ください!
TECH-D-101- Analytics Engineer https://herp.careers/v1/legalforce/hHZ4eGGBc-GD
開発 の求人一覧 - 株式会社LegalOn Technologies https://herp.careers/v1/legalforce/requisition-groups/d2e157cc-120b-4ade-8879-0326c32127bd
参考
1. https://cloud.google.com/looker/docs/system-activity-dashboards?hl=ja#dashboard_recommendations
2. https://cloud.google.com/looker/docs/elite-system-activity?hl=ja
3. https://cloud.google.com/eventarc/pricing?hl=ja
4. https://cloud.google.com/workflows/pricing?hl=ja
5. https://cloud.google.com/storage/docs/pubsub-notifications?hl=ja
6. https://www.googlecloudcommunity.com/gc/日本人コミュニティ-Japanese/Cloud-Functionsを使用してLookerで実行したクエリの結果をBigQueryにロードする/td-p/579963