はじめに
はじめまして、株式会社LegalOn Technologies(職種: データ分析)の上野と申します。現在、データ分析チームに所属し、データとML/AIを用いた営業支援活動を行っております。
2つの既存サービス「LegalForce」と「LegalForceキャビネ」がひとつになり、次世代の法務AI「LegalOn」として産声を上げてから、早いもので2年が経とうとしています。
プロダクトの統合によって、利便性は大きく向上しました。と同時に、サービス形態の変更により、お客様との契約方法も大きくアップデートされております。この新しい環境の中で、弊社営業部門がお客様と密接で継続的なコミュニケーションを行うためには「データによる利用状況の把握」が必要不可欠です。本記事では、お客様の利用実態を把握し、営業活動の起点となる指標「Tier」の開発内容をご紹介いたします。
ビジネス背景
旧サービス「LegalForce」および「LegalForceキャビネ」では、各サービスのご契約アカウント数に応じて、各製品の全機能をご利用いただけるシンプルな体系でした。対して、新サービス「LegalOn」への統合後は、お客様のビジネスニーズや活用シーンに合わせて、各機能を個別にご契約いただける「モジュール型」へと進化しました。また、各モジュールは、ご契約いただいた「ライセンス数」によって柔軟に管理・最適化される仕組みへと変化しています。一方、この製品の進化に伴って、弊社営業部門は、お客様とのコミュニケーション方法をアップデートする必要性が出てきました。
契約単位
| 新・旧 | サービス | 契約単位 | 利用形態 |
|---|---|---|---|
| 旧 | LegalForce | サービス | アカウント保持者が全機能利用可能 |
| 旧 | LegalForceキャビネ | サービス | アカウント保持者が全機能利用可能 |
| 新 | LegalOn | モジュール(機能) | モジュールのライセンス保持者に割り当て |
新旧サービス機能対比表
| (旧)サービス名 | (旧)サービス機能 | (新) LegalOn モジュール |
|---|---|---|
| LegalForce | 契約書レビュー機能 | レビュー |
| 案件管理機能 | マターマネジメント | |
| ひな形機能 | LegalOnテンプレート | |
| 翻訳・英文レビュー機能 | ユニバーサルアシスト | |
| LegalForceキャビネ | 契約書管理機能 | コントラクトマネジメント |
課題
旧サービスにおける利用単位は「サービス」そのものでした。一度ご契約いただければ、アカウントを持つ全てのユーザーが、全機能にアクセスできる構造でした。
しかし「LegalOn」への統合を経て、契約・利用単位は「モジュール(機能)」へと細分化しました。この変化により、営業部門には、お客様が「どの機能を」「どれだけのライセンス枠で」使いこなせているかという、より高度な利用状況の把握が必要になりました。そこで、まず顧客の「モジュール(機能)」ごとの利用率、つまりライセンス保持ユーザーがどの程度使っているかをKPIとして設定しました。
ここで、「どの程度の利用状況であれば、十分に活用いただけていると言えるのか?」という評価基準の策定が問題になりました。お客様ごとに契約モジュールの組み合わせやライセンス数、弊社とのご契約履歴、お客様の事業形態と企業規模など、利用状況に影響する要因があまりに多様であり、特定の数値で利用状況を判断することを、不適切と考えたからです。
加えて、契約更新・解約データがほとんどなかったことも大きな障害でした。本来であれば、これらを「教師データ」として「活用状況」をクロス集計や機械学習を用いて逆算できます。しかし、「Tier」の開発に着手したのはリリース1年後のこと。当時は、十分な契約更新サイクルを経ておらず、判断材料となる実績データは、ほとんど存在しませんでした。
解決策
この「正解がない」という難題を解決するために私たちが考えたのは、契約データが蓄積されるのを待つのではなく、お客様の属性や利用モジュール、ご契約履歴に基づいた「あるべき利用率のガイドライン」を自ら策定し、それを基準に活用状況を評価するというアプローチです。「過去の統計」ではなく「理想の定義」から逆算するーーこのアイデアが、新指標「Tier」開発の大きな転換点となりました。
私たちはガイドラインを推定するために、新たに機械学習モデルを開発しました。この機械学習モデルが、お客様ごとにカスタマイズされた利用率の理想の期待値(ガイドライン)を推定します。さて、次に問題になるのが、お客様の実績値と、得られたガイドラインの両者をどう評価するか?です。
ここで注目したのが、「ガイドラインの妥当性(ばらつき)」を考慮するという視点です。もし、基準となるデータの「ばらつき」を特定できれば、「お客様の利用率とガイドラインとの差」を「ばらつきの程度」で評価することで、その乖離を「統計的にどの程度、異常または良好と言えるのか」を定量的に算出できます。つまり、単なる「差分」を見るのではなく、データの散らばり具合を物差しとして、個々のお客様の活用状況を「客観的なスコア」として適切に位置づけることができます。これら指標を、お客様の契約モジュールごとに算出し、利用状況を評価することにしました。
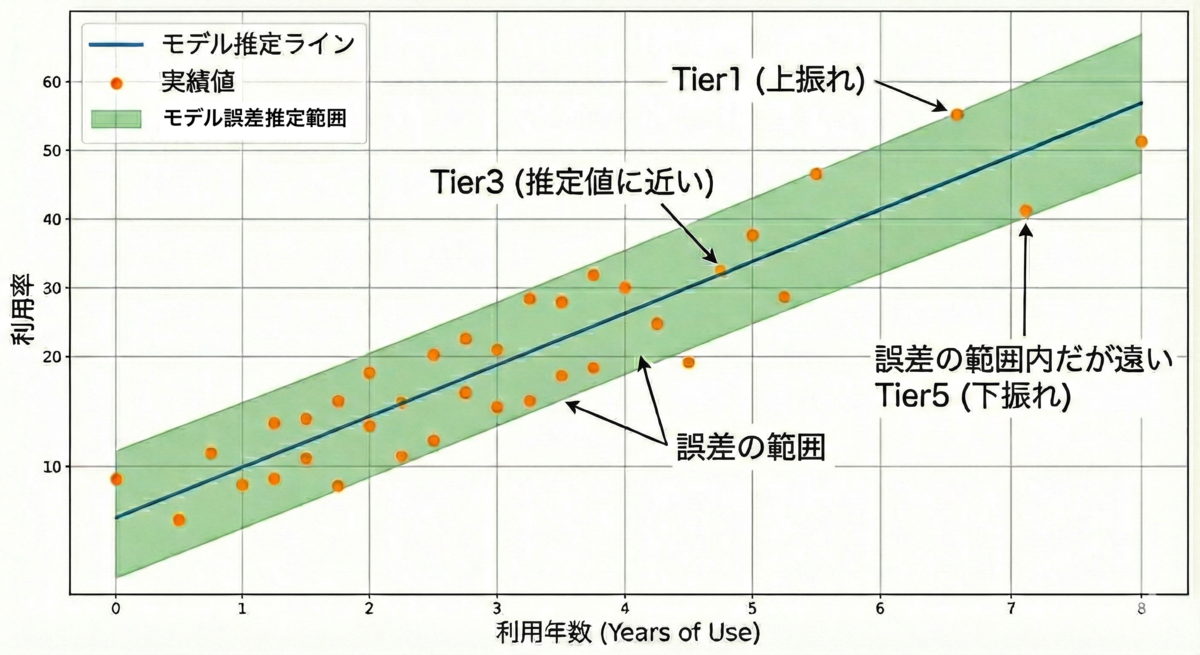
モデリングとTier割り当て
これらの推定値を精緻に算出するため、モデル構築にXGBoostを採用し、評価関数にはピンボール誤差(Pinball Loss)を用いました。ピンボール誤差とは、実際の値が予測値より「大きい場合」と「小さい場合」で、誤差に対するウエイトをを非対称に変化させる損失関数です。この関数を最小化するように学習を進めることで、中央値に加えて「下位◯%」や「上位◯%」といった特定の分位点を直接推定することが可能になります。例えば、alpha=0.5 と設定すれば中央値を、alpha=0.975と設定すれば「上位2.5%の境界線」をピンポイントで予測できるため、お客様ごとにカスタマイズされた多段階の「利用ガイドライン」を構築するのに最適な手法です。
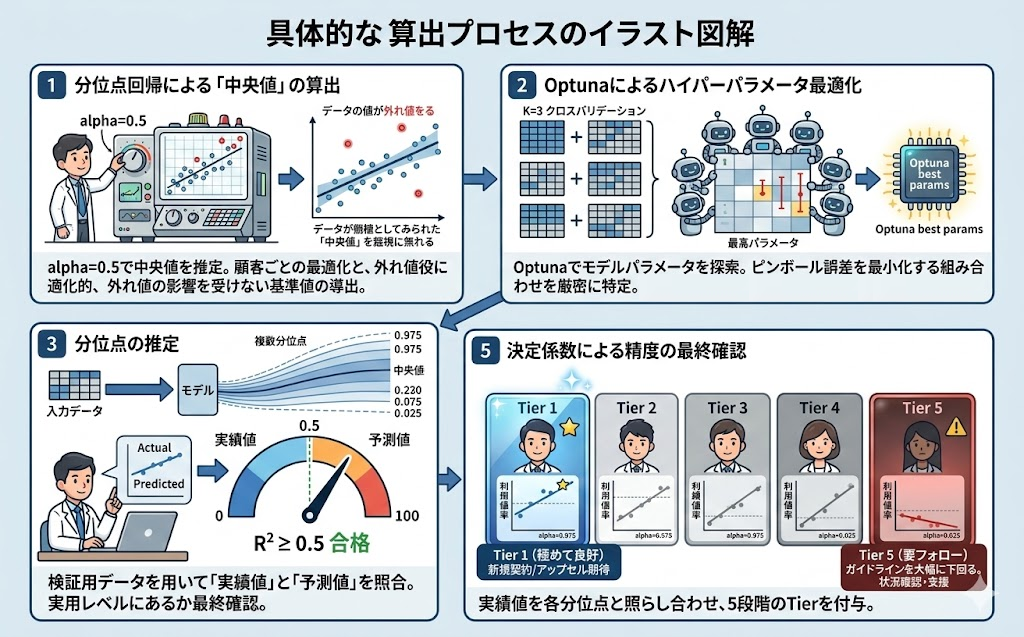
| 1 | 分位点回帰による「中央値」の算出 | まず、alpha=0.5として中央値を推定する分位点回帰を構築します。これにより、顧客属性や契約内容ごとに最適化された「利用率の期待値(条件付き中央値)」を算出します。一般的な平均値ではなく、あえて中央値をターゲットにすることで、一部の極端なデータ(外れ値)に引きずられない、より実態に即した基準値を導き出すためです。 |
| 2 | Optunaによるハイパーパラメータ最適化 | モデルの精度を最大限に引き出すため、Optunaを用いて最適なモデルパラメータを探索しました。この際、データを3つのグループに分けた「クロスバリデーション(交差検証)」を行い、ピンボール誤差を最小化する最適な組み合わせを厳密に特定しています。Optunaは、ベイズ最適化を用いて、膨大なパラメータの組み合わせの中から効率的に最適な値を探索する、日本発のオープンソース・ライブラリです。 |
| 3 | 分位点の推定 | ステップ1・2で構築した最適モデルを用い、分位点用のパラメーター(alpha)を [0.025(2.5%), 0.16(16%), 0.38(38%), 0.61(61%), 0.84(84%), 0.975(97.5%)] と変化させて、分位点ごとの期待値を算出しました。これにより、単一の基準点だけでなく、「そのお客様にとっての利用率のばらつき(分布)」を多段階で把握することが可能になります。この複数の分位点が、最終的なTier判定の「境界線」となります。 |
| 4 | 決定係数による精度の最終確認 | ステップ1・2で最適化されたモデルに対して、学習には一切使用していない検証用データを用いて最終確認をしました。検証用データから作成された「中央値」と「実績値」を照らし合わせ決定係数を計算しました。本プロジェクトでは、この決定係数が「0.5以上」であることを、モデルが実用レベルにあるかどうかの合格ラインとして管理しています。このプロセスを経ることで、特定のデータに依存しない、汎用性の高い「利用ガイドライン」の構築を実現しました。 |
| 5 | Tier割り当て |
最後に、ステップ3で推定した各分位点を「境界線」として、お客様の実際の利用率(実績値)を評価し、5段階のTierを付与します。具体的には、そのお客様の属性や契約条件において推定された分布の中で、実績値がどこに位置するかを判定します。
|
結果
「探索」から「アクション」へのシフト
これまで営業担当者は、膨大な利用ログの中から「どのお客様のフォローが必要か」を自力で探し出す必要がありました。しかしTierの実装により、データを開いた瞬間に優先順位が明白になりました。データを探す手間がゼロになり、「お客様と対話する時間」という本来の業務に集中できる環境が整いました。
「攻め」のフォローアップの実現
利用が滞っているお客様(Tier 5)を即座に特定できるようになったことで、これまでの「お問い合わせを待つ受動的なサポート」から、「異変を察知して先手を打つ能動的なフォロー」へ進化しました。
共通言語としてのTier
さらに、Tierは社内の「共通言語」としても機能し始めています。感覚値ではなく「Tier 2を1へ引き上げるためには?」といったデータに基づいた戦略会議が可能になり、組織全体でのカスタマーサクセスの解像度が向上する基盤となりました。
まとめ
今回のTier開発はゴールではなく、データドリブンな組織への第一歩と考えています。今後はこの精度をさらに高めるとともに、AIを活用したレコメンド機能など、お客様が「LegalOn」を通じてより大きな成功を掴めるような仕組みづくりを加速させていきます。
謝辞
営業側窓口の宮本さんには、業務背景をたくさん教えていただき、大変助かりました。また、モデル検証にお付き合いただき、現場観点から多くのアドバイスをくださったカスタマーサクセスチームの小川さん・辻川さん・野々上さんにも、改めて御礼申し上げます。
仲間募集!
LegalOn Technologiesでは、一緒に働く仲間を募集しています。ご興味のある方は以下のリンクからぜひご応募ください。お待ちしております。