はじめに
はじめまして、こんにちは。LegalOn TechnologiesでHead of Dataをしている若菜です。データ部門では、データアナリスト、データエンジニア、アナリティクスエンジニアが所属しており、日夜データに関連する施策に取り組んでいます。
記事タイトルにもある「データガバナンス」と聞くと、ルールで開発を縛る"守り"の活動をイメージされる方も多いかもしれません。しかし私たちは、ガバナンスは開発を止めるものではなく、加速させるものだと考えています。明確な基準があるからこそ、開発者は「このデータを使って良いのか」と迷う時間がなくなり、安心してデータを活用できる。結果として、事業のスピードが上がる。この好循環が必要です。
今回は、この攻めと守りを両立するための文化を作るために当社で運営している「データワーキンググループ(Data Working Group、以下DWG)」について紹介します。データマネジメントとガバナンスを組織横断的に強化し、同時に事業部門がデータを安全かつ迅速に活用できる体制を整えるための専門部会としてDWGを立ち上げ、私はこのDWGにて議長を務めています。
本記事では、DWGがどのような体制で、具体的にどのような活動をしているのかをご紹介します。
対象読者
- プロダクトの急成長に伴い、データの扱いに課題を感じているエンジニアやデータチームの方
- データガバナンスの体制づくりを検討している責任者の方
ナレッジとして持ち帰れること
- 組織横断のデータガバナンス体制を「どう始め、どう回すか」の実践的なフレームワーク
- AIを活用したガバナンス運用の具体例
データワーキンググループ(DWG)とは?
DWGは、コーポレート部門が統括するセキュリティ委員会の分科会として設置された、データに関するアクティビティを統括する会合です。従来、セキュリティや法務のチェックは各部門で個別に行われることもありましたが、DWGはデータにフォーカスしたステアリングコミッティのような役割を果たします。
DWGの具体的な活動内容
DWGでは、後述する情報資産ガイドラインをもとに、それぞれのプロダクトや各組織に対して指針の提示、指導、サポートをしています。また、情報資産ガイドライン以外にもいくつかのガイドラインや利用規約について、法規制やコンプライアンス上問題ないかをチェックしています。会社組織全体に対して正しくデータマネジメントとガバナンスが行き届くような体制作りを進めています。
Three Lines Model(3線モデル)の2線組織がDWG
組織のガバナンス、リスク管理、内部統制、内部監査の役割分担を整理するための考え方に、Three Lines Model(3線モデル)があります。以下の3つに分類されます。
第1線: 業務部門・現場マネジメント
事業部門やオペレーション部門が、自らの業務の中でリスクを識別・評価・管理し、内部統制を実施します。つまり「リスクを生む業務を持つ人が、まず自分で管理する」ラインです。
第2線: リスク管理・コンプライアンス等の専門管理機能
ERM(全社的リスクマネジメント)、コンプライアンス、情報セキュリティ、法務、品質管理、財務統制などの機能が、第1ラインを支援・助言し、方針や基準を整備し、モニタリングします。第1ラインそのものの代わりではなく、管理の枠組みを強くする役割です。
第3線: 内部監査
内部監査は、経営管理から独立した立場で、ガバナンス、リスク管理、内部統制の有効性について客観的なアシュアランスと助言を提供します。第1・第2ラインを“実行する”のではなく、独立して評価する点が本質です。
このうち、DWGは第2線を担っており、プロダクトが複数存在する中で、データに関連するガバナンスやコンプライアンスに準拠できるような仕組みを整えています。
主な参加メンバー
特徴的なのは、そのメンバー構成です。開発部門だけでなく、以下の役職者が一堂に会して議論します。これにより、技術的な観点だけでなく、法律・契約・監査の観点を含めて合意形成し、スピーディーに方針を決定できる体制を整えています。
- データマネジメント責任者
- 法務担当
- セキュリティ責任者
- 内部監査担当
- 開発統括者
設立の背景: グローバル展開と基準の標準化
なぜ今、DWGが必要だったのでしょうか?きっかけは、データの取り扱いに関する意思決定の非効率さでした。
従来、新しいデータ活用の施策を進めようとすると、まず法務に問い合わせ、次にセキュリティに確認し、さらに開発観点でのチェックを経て……と、いわばスタンプラリーのようなプロセスを踏む必要がありました。これは時間がかかるだけでなく、確認の順序や担当者によって観点が漏れるリスクも抱えていました。
一方で、サービスの拡大やグローバル展開に伴い、GDPRなどの法規制を考慮したデータ移転ルールや、グローバル共通の基準作りも急務となっていました。各国の開発者がデータをどのように管理すべきか、具体的な基準が必要でした。さらに、ルールが形骸化しないよう基準を常にアップデートし、システムに正しく取り込まれる管理体制の構築も求められていました。
AIガバナンスにおけるガードレール整備
LLMをはじめとするAI技術の急速な進化により、コーディングエージェントやAIツールが社内のデータやドキュメントを参照して開発を支援する時代が到来しています。このとき、エージェントが参照する情報の機密レベルが曖昧なままでは、意図せず機密データが外部サービスに送信されたり、不適切な形で利用されるリスクがあります。情報資産の分類と取り扱い基準を明確に定めておくことが、AIエージェントに対するガードレールとしても機能するのです。
こうした背景から、法務・セキュリティ・開発の意思決定者が一堂に会し、AI活用と事業成長を安全に推進するための合議体としてDWGを設立しました。スタンプラリーを解消し、一つのテーブルで迅速に判断できる体制を整えることが、攻めと守りの両立への第一歩でした。そのためのガードレールとして整備したのが、情報資産ガイドラインです。
情報資産ガイドラインとは?
情報資産ガイドラインとは、データに関する具体的な対応方針を、利用規約・法規制・コンプライアンスの観点からまとめたものです。当社では、以下のような観点を盛り込んで運用しています。
- セキュリティの原則(機密性・完全性・可用性)に基づく考え方に基づいたセキュリティ対策の提供
- ガイドラインをもとにしたプロダクト・各組織へのサポートと指導、Custom GPTやClaude Code等のコーディングエージェントを活用した具体的な対策への誘導
この取り組みには、弊社の従業員がこの情報を把握する以外にも重要な側面があります。昨今、ChatGPTやClaude CodeといったLLM・コーディングエージェントが開発現場に浸透する中で、エージェントがどのレベルの情報を参照してよいのかという課題は多くの企業が直面しているテーマです。DWGが整備した情報資産ガイドラインは、このガードレールの仕組みを担う役割を持っています。
セキュリティの原則(機密性・完全性・可用性)に基づく考え方
ガイドラインを作成する上で、セキュリティの基準が必要です。
そこでDWGでは、政府機関等の統一基準を参考に、「機密性(Confidentiality)」「完全性(Integrity)」「可用性(Availability)」の3つの要素に基づいて機械的にレベル分けを行う方式を採用しました。例えば機密性に焦点を当てたレベル分けは以下のとおりです。
| 機密性レベル | 定義・判断基準 | アクセス制御・取り扱い (情報資産レベル) |
|---|---|---|
| 機密性 5 | 最高機密 漏洩により組織の存続や事業継続に「深刻な」損害を与える可能性が極めて高い情報。 |
Restricted (5) 最も厳しい制限。特定の権限者のみがアクセス可能。最強度のセキュリティ対策を実施。 |
| 機密性 4 | 最重要情報 漏洩により組織の存続や事業継続に損害を与える可能性が高い情報。 |
Restricted (4) 特定の権限者のみアクセス可能。厳重な管理が必要。 |
| 機密性 3 | 重要情報(法令・規約情報) 個人情報(特定・要配慮を除く)、またはNDAや利用規約等により法的・契約的に取り扱いが規定されている、当社として漏洩時のリスクがある情報。 |
Protected (3) 限られたグループ(プロジェクトメンバー等)での利用を想定。外部への持ち出しは制限。 |
| 機密性 2 | 社外秘・関係者限り 法令等の規定はないが、漏洩すると業務遂行に支障(評判低下、業務遅延、経済的損失など)を及ぼすおそれがある情報。 |
Private (2) 社内限定だが、内部では広く共有可能。外部公開は不可。 |
| 機密性 1 | 公開情報 公開を前提としている、または開示されても業務への支障がない情報。 |
Public (1) アクセス制限なし。外部公開可能。 |
上記のようなレベル分類をもとに、該当する情報資産をより細かい粒度で分けて対処法を記載しています。例えば、契約書のタイトルであればこのセキュリティ対策が必要、という形です。
これらの対策はセキュリティコントロールとして具体的に定義しています。続いて、このセキュリティコントロールの導入について紹介します。
情報資産レベルごとに具体的なセキュリティコントロールの導入
それぞれの情報資産に対して開発者が何をすればよいのか、判断が難しいのが常です。そこで、具体的に何をすべきかを以下4つの観点から記載しています。

- 予防
- 防止・防御
- 検知・追跡
- 回復
この4つの観点で具体的なセキュリティ対策を記載しています。例えば、予防の対策として、Google CloudのIAM認証時にPAM(Privileged Access Manager)を使用した一時的なアクセス権限付与のフローを整備すること、といった形で導入すべきセキュリティコントロールの内容を案内しています。
ベースライン・リスクベース・ビジネスプロセスアプローチによるセキュリティコントロールの適用判断
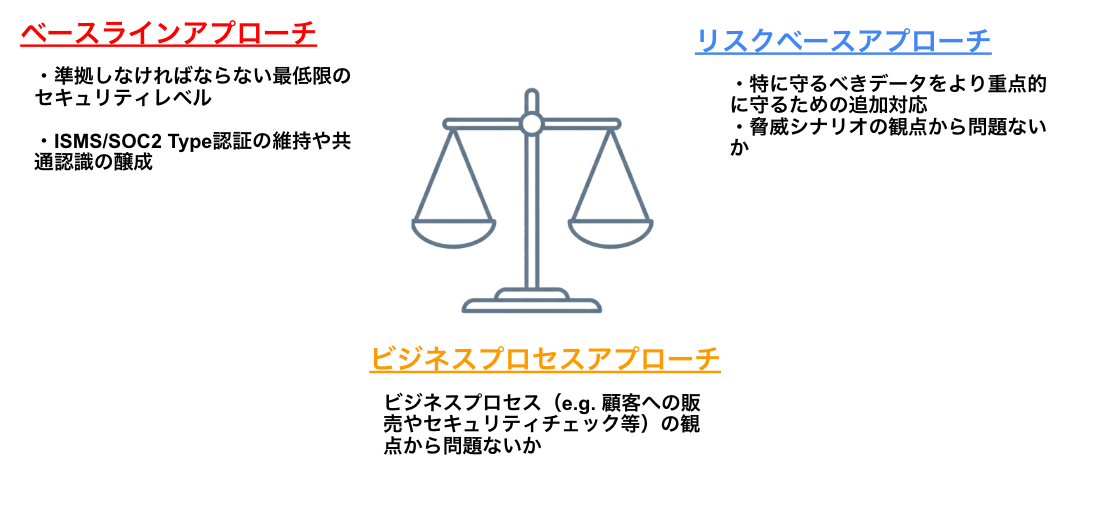 セキュリティ対策において、前述したセキュリティコントロールを導入するにあたり、すべてのデータに最高レベルの防御壁を築こうとすると、コストと工数が肥大化し、開発スピードを損なってしまいます。そこで私たちは、「ベースライン」で足元を固めつつ、「リスクベース」と「ビジネスプロセス」で要所を締めるというハイブリッドな戦略を採用しました。
セキュリティ対策において、前述したセキュリティコントロールを導入するにあたり、すべてのデータに最高レベルの防御壁を築こうとすると、コストと工数が肥大化し、開発スピードを損なってしまいます。そこで私たちは、「ベースライン」で足元を固めつつ、「リスクベース」と「ビジネスプロセス」で要所を締めるというハイブリッドな戦略を採用しました。
ベースラインアプローチ:法令・規格への適合
これは、組織として必ず守らなければならない最低限の基準です。 具体的には、法律(個人情報保護法など)、取得している認証(ISO/IEC 27001等)、そして顧客との約束である利用規約に基づいた必須のセキュリティ対策を指します。
開発者は、「このデータは機密性が高いため、標準のアクセス制御に加え、IP制限と多要素認証を追加しよう」といったように、状況に応じた判断と実装ができます。
リスクベースアプローチ:脅威シナリオからのリスク評価
ベースラインという土台の上に、守るべきものをより重点的に守るために追加するテーラーメイドの対策です。すべてのデータが同じリスクに晒されているわけではありません。データの特性(機密性が高い契約書データなど)や具体的な脅威シナリオを評価し、ベースラインだけではカバーしきれない高度な脅威に対してリソースを集中させます。
ビジネスプロセスアプローチ:事業観点での評価
ビジネスプロセスの観点から「どうすればできるか」を考えることも重要です。データガバナンスはNGを出すための仕組みではありません。例えば、新しいSaaSにデータを連携したいという相談があった場合、単にリスクを指摘して終わるのではなく、「この条件を満たせば利用可能」「データを匿名化すれば情報資産レベルを下げて活用できる」といった実現可能な代替案を提示します。顧客への販売プロセスやセキュリティチェックといったビジネスプロセスへの影響も考慮し、事業の推進とガバナンスを両立させる判断を下します。セキュリティ・法務・開発の意思決定者が同じテーブルについているからこそ、その場で合意形成し、Go/No-Goの判断ができる点がDWGの強みです。
実際のガイドラインの内容
 前述したそれぞれの対応について、実際のガイドラインの画面を共有します。一部公開が難しい情報を含むためほとんどの内容はお見せできませんが、前述した内容を盛り込んだ形で対策が列挙されています。
前述したそれぞれの対応について、実際のガイドラインの画面を共有します。一部公開が難しい情報を含むためほとんどの内容はお見せできませんが、前述した内容を盛り込んだ形で対策が列挙されています。
- CIA別のレベル分け
- 機密性
- 完全性
- 可用性
- 重要データか否か
- 具体的なセキュリティコントロールの内容
- 予防、防止・防御、検知・追跡、回復の4カテゴリ別
- ベースラインとして何をすべきか、リスクベースとしてどのような追加対応が考えられるか
ChatGPT / コーディングエージェントによる一次判断
運用面での工夫として、問い合わせの一次受けにCustom GPTやClaude CodeやCodexなどのコーディングエージェントを導入しています。 ガイドラインの内容は広範にわたるため、まずはAI経由で自己解決を促し、それでも解決しない複雑な課題(法務・セキュリティ・製品が複合的に関わる問題)について、Slackや定例会で議論するフローを構築しました。
また、ガイドラインは複雑なため、一見してもすぐに理解することは難しいため、GPTで開発者自身が必要な情報にのみすぐにアクセスできる仕組みを整備することでシステムへの反映がしやすいように工夫しました。
これにより、各プロダクトチームがフローチャートに従って、統一された基準でデータを分類できる体制を構築しています。例えば、エンジニアが仕様を決める際、「これは機密性3で、情報資産レベルとしては3だから、ベースラインとしてGoogle Cloudやアプリケーションではこの設定が必要」とロジカルに判断できるようになった点がメリットです。
 以下は、Custom GPTである情報資産について、どのようなレベルのデータに該当するのかを問い合わせした結果です。ガイドラインに基づきレベル判定されています。
以下は、Custom GPTである情報資産について、どのようなレベルのデータに該当するのかを問い合わせした結果です。ガイドラインに基づきレベル判定されています。
 実際には、上記の画像の下にさらに具体的なGoogle Cloud等におけるセキュリティ対策が記載されています。今回は直接画面を共有できませんでしたが、例えば以下のような対策が含まれています。
実際には、上記の画像の下にさらに具体的なGoogle Cloud等におけるセキュリティ対策が記載されています。今回は直接画面を共有できませんでしたが、例えば以下のような対策が含まれています。
- VPC Service Controlsで BigQuery / Cloud Storage / Pub/Sub 等の周辺サービスをデータ境界内に囲い、外部へのデータ持ち出しを防止する
- サービスアカウント鍵の発行禁止、Workload Identity連携を利用する
- Cloud HSMやCMEK(Customer-Managed Encryption Keys)を使用したデータ暗号化を実施する
過去のやりとりについて保存・整合性を保つ
それぞれガイドラインに準拠しているかをチェックするにあたり、法的解釈を踏まえた上での回答や、複雑なセキュリティ要件をクリアにするための仕組みの提案など、これらのデータガバナンスに関するナレッジは貯まっていきます。
そこで、これらの過去のやりとりをナレッジデータベースとして全て保管し、前述したChatGPT / コーディングエージェントで過去の判例内容として参照できるようにしました。こうすることで、当時の意思決定を瞬時にAIが把握し、それに基づいた回答ができるようになりました。
これにより、さまざまなディスカッションが行われる中での道標にもなっています。Slack等で流れてしまう情報、定例での情報もAIが把握できるように整えることで、有効活用できる良い事例になっていると思います。
今後の展望
現在は、データセキュリティやガバナンス、リスク管理に重点を置いていますが、将来的にはデータ品質やAIによる自動チェック体制といった領域までスコープを広げていく方針です。
特に今後チャレンジしたいのは、組織全体がガイドラインや利用規約に準拠できているかを、システムの構成やDesign Doc、詳細設計書からデータを取得し、AIで監査・チェックする仕組みです。現在のAI技術の進化を踏まえると、2026年度前半には実現を目指しており、導入・運用の際には改めて紹介する予定です。
これからも、組織全体でデータの価値を最大化しつつ安全に活用できる体制を提供するために、DWGは活動を続けていきます。
まとめ
ここまで記事を読んでいただきありがとうございます。以下は、本記事で紹介したDWGの全体像をGeminiの画像生成機能(Nano Banana: Notebook LM)で生成したまとめです。
 データガバナンスは守りの活動と思われがちですが、明確なルールと相談体制としてDWGがあることで、開発者やデータの利用者が運用ルールに疑問を感じた場合や、事業部側で判断に迷う場合の相談窓口として機能します。また、当社の製品を利用される顧客の観点でも、データがどのように保護されているかを明確化することで、安全にご利用いただくことにも繋がります。
データガバナンスは守りの活動と思われがちですが、明確なルールと相談体制としてDWGがあることで、開発者やデータの利用者が運用ルールに疑問を感じた場合や、事業部側で判断に迷う場合の相談窓口として機能します。また、当社の製品を利用される顧客の観点でも、データがどのように保護されているかを明確化することで、安全にご利用いただくことにも繋がります。
その上で、過去課題となっていた意思決定のスピードについても、AIを活用した開発に即した仕組みを整えました。グローバルにサービスを展開していく中で、各国ごとに異なる法規制やコンプライアンス要件に対応する必要があります。本ワーキンググループを継続して運用しつつ、AIによるチェック体制を組み合わせることで、より安全かつスピーディーな体制を目指していきます。
本記事が、データガバナンスや組織づくりに関心のある方の一助になれば幸いです。今後もテックブログを通じて、私たちのデータマネジメント・ガバナンスへの取り組みを発信していきます。
仲間募集!
データチームでは仲間を募集しています。関心のある方はぜひご応募いただければ幸いです。
TECH-D-101- Analytics Engineer - 株式会社LegalOn Technologies